Технические аспекты цифровой текстологии
09.09.2021
Данная статья была написана несколько месяцев назад для обсуждения вопросов организации текстологической работы. Текущий вариант размещается в неизмеренном виде, так как корректировки на данный момент не имеют смысла — для детализации спорных вопросов необходимы отдельные тексты или готовые технические решения.
Текстология ставит перед собой три основные задачи [1]:
- Установление авторского текста;
- Организация текста, его компоновка, установление состава и композиции для отдельных изданий;
- Комментирование текстов.
Достижение этих целей посредством цифровой техники связано с отличными от бумаги проблемами, однако, открывает недоступные для бумаги возможности. В этой статье мы обозначим проблемы цифровой текстологии и наметим пути их решения.
Текстология как процесс, настроенный под обстоятельства
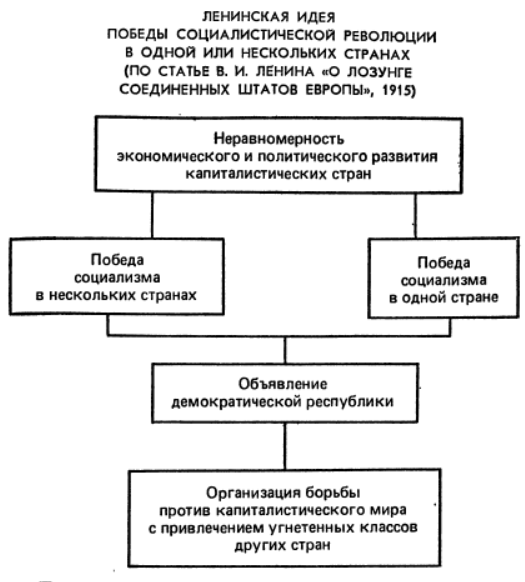
Прежде всего, рассмотрим понимание текстологии как процесса. Канонический, выверенный текст мы имеем условно, только как самый последний вариант установленный в данный момент. Новые данные и исследования могут привести к новой версии канонического текста. Хоть в данный момент мы и утратили государственные институты без которых подобные исследования труднореализуемы и просто используем прошлые наработки, в будущем подобная работа будет возобновлена. Таким образом текстологический процесс должен учитывать возможность изменения текста.
Технические и организационные моменты работы тоже не застыли во времени, а изменяются. Учитывая это, при принятии решений следует выбирать разумный компромисс между возможностями и простотой решения. Чем проще средство или решение, тем проще его изменить или заменить в будущем. А исследовательские задачи, задачи по созданию чего-то нового, редко в точности следуют заранее спланированному детальному плану. Обычно, во время процесса построения нового выявляются особенности и детали, которые позволяют принять намного более эффективное решение, чем с информацией которая была в начале. В такой ситуации, при планировании лучше придерживаться следующего принципа: принимать важное решение, которое в будущем будет трудно изменить, как можно позже, когда негативный эффект от не принятого решения больше, чем принятие потенциально неверного решения.
Кроме того технические возможности, опыт и понимание задач у разных групп занимающихся текстологией различны. Не всегда будет полезна стандартизация всех под единообразные требования. Обмен между сообществами, как результатами работы, так и опытом необходим. В то же время всегда стоит учитывать и использовать конкретные обстоятельства места, времени и коллектива.
Цифровое представление информации
Идея автоматизации текстологической работы не является новой. Можно встретить упоминание о первых таких попытках около 1955 года [2]:
Сделаны уже первые попытки механизировать сличение текстов разных экземпляров одного издания. Специальным прибором произведено сличение разных экземпляров первых изданий Шекспира — основных источников его текста (рукописи, как известно, отсутствуют). В итоге машина приблизительно в 40 раз быстрее, чем это мог бы сделать человек, сравнила 75000 страниц двухколонного текста и при этом обнаружила несколько сот неизвестных ранее разночтений.
С того времени технологии существенно развились и для дальнейшего рассуждения необходимо кратко рассмотреть их современное состояние.
Для упрощения огромной сложности компьютерных систем используются слои абстракции. Каждый слой скрывает за собой внутреннее, реальное устройство более низких уровней и предоставляет упрощённое описание, подходящее для более высокоуровневой работы. Без такого деления, любая деятельность требовала бы знания и учёта огромного массива информации и была бы невозможна.
Это похоже на сокрытие внутреннего устройства автомобиля за капотом. Водителю предоставлены удобные средства управления в виде руля и педалей. Между средствами управления и движением машины есть прямая и простая зависимость: руль влияет на направление, а педали на скорость. Таким образом при управлении не требуется учитывать как именно и какие именно детали конкретного двигателя приходят в движение при ускорении, достаточно понимать зависимость нажатием педали и скоростью. За счет этого, с одной стороны, проще обучение вождению, а с другой пересесть с одной модели автомобиля на другую не составляет особого труда. Так и работают две функции абстракции: с одной стороны она уменьшает сложность, а с другой скрывает реальную реализацию.
Уровень, с которого мы начнем — представление данных в виде упорядоченной последовательности бит. Этот уровень позволяет нам не рассматривать физические свойства хранения информации: хранится ли она на SSD или HDD, или передается в данный момент по сети, что для нашей работы не имеет значения. В то же время мы сможем отразить все важные для текстологии аспекты.
Один бит можно представить в виде цифры: ноль или единица, а последовательность бит в виде ряда из нулей и единиц. Например, так
010101101111100110010101010100101
В подавляющем большинстве современных реализацией компьютерных систем этот ряд дополнительно группируется на блоки по 8 цифр называемых байтами:
01010110 11111001 10010101 01010010
Сами по себе данные в таком виде бесполезны. Нам не интересны просто последовательны цифр. Для того чтобы приносить пользу данным задается специальная структура. Структура задаётся как внешнее описание, данные сами по себе остаются в виде последовательности нулей и единиц.
Например, мы можем договориться, что будем кодировать цвет двумя битами. Таким образом мы сможем задать четыре разных цвета:
00 --- Белый
01 --- Чёрный
10 --- Красный
11 --- Зелёный
Теперь, если нам передадут данные в которых закодирована последовательность цветов
10000111
Мы понимаем что эта последовательность кодирует следующие цвета: красный, белый, чёрный, зелёный.
С другой стороны, мы можем договориться что будем считать группу из четырёх бит целыми, положительными числами. Одной, такой группой, мы можем закодировать 16 различных чисел. Например, мы решили кодировать числа от 0 до 15:
0000 = 0
0001 = 1
0010 = 2
0011 = 3
0100 = 4
...
0111 = 14
1111 = 15
Последовательности бит остаются такими же, но наши договорённости наделяют их различным смыслом, мы используем разный способ интерпретации одних и тех же данных.
Теперь нам ничего не мешает объединить цвета и числа в один формат. Представим, что в начале в начале должны идти два числа определяющие размеры изображения в точках, а затем последовательность цветов точек изображения, начиная с левого верхнего угла. Можно заметить, что уже произошел переход на следующий уровень абстракции: этот формат описан не в понятиях нулей и единиц, а в понятии чисел и цветов, хотя, на более низком уровне цвета и числа закодированы последовательностями бит.
Рассмотрим пример
01000100 01000001 00111100 10000010 00101000
Данное изображение может выглядеть так:
Описанный способ используется для кодирования изображений, хотя сейчас популярны более современные способы кодирования изображений.
Кодировки текста и Юникод
С текстом ситуация обстоит точно так же как с цветами. Алфавит, вместе со знаками препинания, представляет собой множество символов, каждый из которых нужно закодировать. Для этого используются кодировки — таблицы соответствия между заданными последовательностями бит и символами алфавита. Говоря о кодировках и символе, всегда имеется в виду содержание символа, как элемента определенного алфавита, а не его конкретное начертание в определённом шрифте.
Указание что
01101110 = символ «n» английского алфавита
...
01101111 = символ «o» английского алфавита
говорит только что определённый код соответствует символу и определённого алфавита. Как будет выглядеть этот символ когда его увидит человек зависит от других факторов, которые мы обсудим далее.
Наиболее известной является 7-битная кодировка ASCII. Она включает в себя символы английского алфавита, знаки препинания и служебные символы. Для примера, символ «g» в ней кодируется последовательностью бит «1101011». Но кроме английских букв необходимо хранить символы других языков. Из этой необходимости появились однобайтовые национальные кодировки.
Если кодировать текст из расчета один 8-битный байт на один символ, что было очень удобно и эффективно из-за технических особенностей, при малой мощности аппаратных систем, то остаётся один, незадействованный кодировкой ASCII бит. Этот бит позволяет добавить к таблице кодировки дополнительные 127 символов. Подобные кодировки были разработаны для разных национальных языков и компьютерных платформ. Например, для кириллицы была популярной кодировка win-1251. В неё половина таблицы полностью соответствует ASCII, а вторая половина содержит дополнительные символы, например:
01101101 = латинская «m»
...
11101101 = кириллическая «н»
Такой способ давал относительную совместимость: английский текст при использовании любой кодировки отображался верно, а чтобы расшифровать текст с национальным алфавитом, нужно было знать в какой кодировке он был закодирован. При чтении текста в неверной кодировке он выглядел как набор случайных символов. Другими проблемами были необходимость производить преобразование из одной кодировки в другую и недостаточность количества символов в однобайтных кодировках для представления некоторых языков.
С развитием мощности компьютерных систем появились новые возможности кодирования текста. Современным мировым стандартом для этих целей является Юникод. Таблица символов Юникода определяет соответствие между заданным числом и символом называемое кодовой точкой [3]. Речь пока идёт о простых числах, вроде 4, 23 и 3453. Существует достаточное количество чисел чтобы закодировать все мировые языки, большой набор знаков, спецсимволов и чего-угодно ещё.
Наличия таблицы соответствия чисел и символов недостаточно. Для хранения текста нам нужно знать какая последовательность бит соответствует определённому символу. Для этого используются кодировки UTF-8, UTF-16BE, UTF-16LE и др. Наиболее популярна UTF-8, за счет своей совместимости с ASCII и часто наименьшего размера.
Совместимость UTF-8 с ASCII означает что последовательности бит для кодирования символов английского алфавита в этих кодировках совпадают, как и в случае с однобайтовыми национальными кодировками. По той же причине в названии присутствует число 8 — минимальное количество бит необходимых для хранения одного символа в этой кодировке. Если для английского символа нужен один байт, то для символов других алфавитов их понадобиться большее количество, например
11010001 10001011 = кириллическая буква «ы» в кодировке UTF-8
Другие юникодные кодировки, вроде UTF-16LE, так же определяют параметры соответствия последовательности бит символам и различаются минимальной длиной для хранения одного символа и порядком байт.
Благодаря своей структуре Юникод позволяет полностью решить все проблемы связанные с обменом текстовой информацией: нет необходимости перекодирования из одной кодировки в другую, в кодировке есть символы для представления всех используемых языков и таблица символов регулярно пополняется. Текстологическая работа ориентирована на многоязычность, исходя из этого выбор Юникода для текстологической работы не имеет альтернатив. Обсуждаемым вопросом можно считать какую именно юникодную кодировку использовать.
Так как как юникодные кодировки свободно конвертируются друг в друга, то обязательным требованием можно считать только указание используемой кодировки в работе. Выбор же определенной кодировки можно произвести из анализа конкретной ситуации. UTF-8 удобно использовать из-за повсеместной поддержки и минимально размера если текст содержит много английских символов как, например, HTML разметка. С другой стороны, для китайского языка более оптимальным по размеру, скорее всего, окажется UTF-16.
Бинарные и текстовые форматы
После выбора способа кодирования символов у нас остаётся неразрешённым вопрос о том как кодировать не символьную информацию. Ведь автор, обычно, не производит просто последовательность символов, а делит текст на заголовки, абзацы и применяет другие способы выделения текста. С помощью кодировки мы можем закодировать последовательность символов, но как отделить заголовки от абзацев? Как и в примере с изображением, мы можем определить свой формат: сопоставить типы блоков текста, такие как абзац и заголовок и определенные последовательности бит, а затем объединить это с текстом в заданной кодировке. Например, формат может быть таким:
- Документ состоит из блоков;
- Каждый блок начинается с заголовка блока и тела блока;
- Заголовок включает в себя два однобайтовых поля: тип блока и длину тела блока в символах;
- Тело блока состоит из символов в однобайтовой кодировке.
Для типов блоков используем сопоставление
00000001 --- Заголовок
00000010 --- Абзац
Для упрощения, представим что мы используем однобайтовую кодировку win-1251 для кодирования символов. Текст состоящий из заголовка «1.» и абзаца «Привет» будет закодирован следующей последовательностью бит:
00000001 00000010 00110001 00101110 00000002 00000110 11001111
11110000 11101000 11100010 11100101 11110010
В этом формате можно заметить смешение двух подходов: часть информации закодирована с помощью текстовой кодировки, а часть по заданным отдельно сопоставлениям. Такие форматы называются бинарными, так как содержат нетекстовые данные.
Практика показала неудобство бинарных форматов, в особенности, для хранения текстов. К их недостаткам относится необходимость в специальном средстве для просмотра и редактирования. Файлы в таком формате нельзя редактировать через обычный текстовый редактор. Причем какие-то универсальные средства, вроде Hex-редактора тоже будут не удобны, только специально написанная под эту задачу программа. Это существенно ограничивает распространение и универсальность таких форматов.
Альтернативой бинарным форматам являются текстовые форматы. Вся информация в них закодирована с помощью символов и их последовательностей. Например, мы знаем, что в тексте абзац не может начинаться с символа решётки «#», поэтому договариваемся, начинать с этого символа только заголовки. Закодируем, тот же текст из примера выше в таком виде:
# 1.
Привет
Немного упрощая реальную ситуацию, мы получили данные содержащие эквивалентную информацию, но теперь для их просмотра и редактирования не требуется специальные средства. С таким текстом можно работать на любом устройстве и платформе.
Так как текстологическая работа изначально должна опираться на как можно большую массовость и универсальность, то выбор текстовых форматов логичен. В данный момент большинство форматов для хранения и обработки текстов являются текстовыми форматами. К примеру, первые версии формата файлов Microsoft Word (doc) были бинарными, но позже были заменены на формат на текстовый формат на основе XML, о котором будет сказано далее.
Печатные и непечатные символы
Стоит особо упомянуть, что говоря о символах мы не всегда имеем в виду букву алфавита или знак препинания, а в это понятие включается так же набор непечатаемых символов. Непечатаемые символы — это специальные символы, обычно не выводимые на экран, либо выводимые в особом виде или каким-то способом влияющие на отображение текста.
Пробел это один из непечатаемых символов. Самым распространенным, после пробела, примером является последовательность символов перевода строк. Эта последовательность обычно специфична для платформы, к примеру, в Windows она состоит из двух символов: возврат каретки (CR) и перевод строки (LF). При использовании Unicode текстологическая работа должна проводиться в соответствии со стандартом: допустимы символы CR, LF и их комбинация CR+LF считающиеся одним переводом строки. Для упрощения изложения далее под символом переноса строк понимается любая допустимая Unicode комбинация.
Текстовые редакторы обычно содержат настройки для отображения непечатаемых символов, поэтому их «непечатаемость» относительна. Главное понимать что их сущность не отличается от других символов: для Юникода это просто ещё одна кодовая точка (соответствие определённого числа символу), которая взаимнооднозначно отображается на последовательность бит через кодировку.
Рассмотрим детальнее некоторые непечатаемые символы и способы автоматизации работы с ними.
Неразрывный пробел и другие пробельные символы
Часто абзацы состоят из нескольких строк. Средства отображения текста автоматически разделяют абзац на несколько строк, разделяя текст по словам с помощью пробелов. В некоторых случаях пробелы разделяют слова или группы символов, которые всегда должны оставаться на одной строке, например, сокращения («т. п.», «т. е.») или инициалы («В. И. Ленин»). Чтобы такие слова оставались на одной строке применяются символы неразрывного пробела. Внешне они выглядят как пробелы, но имеют отличный от обычного пробела Unicode код. Если неразрывный пробел находится между словами, то эти слова всегда будут отображены на одной строке.
Неразрывные пробелы можно расставлять вручную, но это с одной стороны трудозатратно, а с другой не эффективно — очень тяжело учесть все места где они необходимы, их гораздо больше чем приведено выше. Несмотря на это, правила расстановки неразрывных пробелов хорошо формализуются, а следовательно их можно автоматизировать. Примеры типографов, автоматизирующих расстановку неразрывных пробелов: typus, Типограф Евгения Лепёшкина, Типограф Муравьёва. Для разных языков, из-за отличий типографических правил понадобиться применять разные средства.
Кроме неразрывного и обычного применяются и другие виды пробелов. Их использование тоже автоматизируется.
Мягкий перенос
Кроме переноса отдельных слов, часто используется перенос части слова на следующую строку. Такой перенос позволяет получить более пропорциональные строки которые удобнее читать. Средство отображение может либо само делить слова по правилам переноса, либо использовать символы мягкого переноса из текста. Символ мягкого переноса ставится между буквами слова в местах где правилами разрешен перенос; если слово находится на границе двух строк и при переносе его части строка получается более пропорциональной, то средство переносит часть слова на следующую строку, а на месте символа мягкого переноса помещает дефис.
Для автоматической расстановки мягких переносов применяется алгоритм Алгоритм Ляна-Кнута и уже есть готовые, основанные на нём, программные средства: pyphen, Hyphenopoly, tex-hyphen и др. Как и в случае с неразрывными пробелами, необходимость ручной расстановки символов мягкого переноса отсутствует.
Обозначим основной принцип: использовать только видимые символы, пробелы и переносы строк, а работу с другими символами стараться автоматизировать.
Другие символы юникода
Отдельно стоит отметить, что автоматизировать можно и работу с печатными символами: длинное тире, знак штриха, дроби и т. п. Для быстрого ввода существуют специальные раскладки, а для автоматизации вышеупомянутые типографы.
Итак, мы можем завершить использование абстракции данных в виде последовательности бит и сосредоточиться на более высокоуровневой абстракции данных как последовательности символов, что упростит дальнейший анализ.
Внешний вид и разметка
Прежде чем рассмотреть какую именно информацию мы хотим зафиксировать в результате текстологической работы остановимся детальнее на принципе отделения внешнего вида от самой разметки. Способ которым мы, в примере выше, выделили заголовок
# 1.
Привет
называется разметкой — набор формальных (строго заданных) правил по которым часть текста выделяется и наделяется особым смыслом. Это похоже на правила по которым мы определяли бинарные форматы, но только более сложные. Правила разметки могут определять какого цвета текст, тип шрифта, является ли текст заголовком или цитатой и любые другие вещи которые авторы разметки захотели выделить в тексте. Назовём подобные правила элементами разметки. Элементы разметки выделяют часть текста (блок) и наделяют его особым смыслом или свойствами.
Элементы разметки можно разделить на две группы: те, что определяет чем является элемент и те, что определяют то как выглядит элемент.
То как текст выглядит зависит от множества факторов. Для начала, пойдет ли текст на печать или будет воспроизведен на электронном устройстве. Для электронного устройства сразу возникают вопросы про тип, размер и цветопередачу экрана. Кроме того, часто сам читающий может настроить параметры отображения текста так как ему хочется. Мы ещё не упоминали про такие специфические формы как автоматическое чтение вслух или конвертеры в азбуку Брайля.
Таким образом, если цель — максимальное распространение и доступность материалов, не имеет смысла и даже вредно задавать в разметке специфические для внешнего вида текста параметры. К таким параметрам относятся: гарнитура и размер шрифта, межабзацное и межстроковое расстояние, выравнивание текста абзацев и др.
С другой стороны, отвлечься от внешнего вида полностью нельзя. Автор не выражает свою мысль исключительно последовательностью букв алфавита и знаков препинания. Могут использоваться разного рода выделения, подчеркивания, композиция текста. Разметка должна иметь все возможности для выражения замысла автора:
Само собой разумеется, что текстолог обязан сохранять в неприкосновенности авторское расположение текста, даже если оно противоречит издательским инструкциям.
«Лесенка» Маяковского, короткая строчка-абзац В. Шкловского или противоречащее, казалось бы, грамматическим правилам расположение строк у В. М. Дорошевича — их творческое достижение и должно быть сохранено. [4]
Выходит, что несмотря на первичность самого текста, некоторые возможности разметки касающиеся внешнего вида тоже необходимы. Конкретный набор таких возможностей требует дальнейшей проработки, которая должна непосредственно опираться на возникающие в текстологической практике примеры. Сейчас же мы можем остановиться только на том, что задача текстологии не сводится к воспроизведению рукописи или бумажного издания в том виде, в котором оно существует, так как для этого полностью подходит только фотокопия. Если для специфической задачи нужен именно такой уровень детализации, то к фотокопии и будет обращаться исследователь.
Развивая эту логику далее, мы приходим к выводу, что нет смысла использовать или брать за основу стандарты направленные на воспроизведение печатного варианта: docx, ODF, RTF, варианты TeX, PDF. Эти форматы с одной стороны предоставляют излишние возможности по управлению внешним видом (а излишние возможности усложняют работу и повышают вероятность ошибок), а с другой все равно не позволяют разметить всю информацию, необходимую для текстологии, так как разметка, по большей части, должна выделять логические аспекты текста, а не его внешнего вида.
Применение средств направленных на форматирование внешнего вида затрудняет дальнейшие задачи по обработке текста: конвертацию, сравнение, комментирование. Участникам текстологической работы, приходиться следить за такими параметрами текста, как размер шрифта или стиль выравнивания текста в абзацах. Такая работа сложно автоматизируется, при необходимости поменять стиль заголовков в нескольких файлах docx или OTD приодеться отредактировать все эти файлы вручную, или использовать специальные программные средства более-менее автоматически редактирующие эти файлы. Решение придумано давно и заключается в отделении разметки, от стилизации внешнего вида. Такого принципа придерживается формат HTML5: разметка (HTML) и стили (CSS) отвечающие за внешний вид могут храниться раздельно. Похожий принцип используется в форматах DocBook и LaTeX.
Отделение внешнего вида от разметки позволяет сосредоточиться при вычитке и других работах на самом тексте, а не на его внешнем виде. Другое преимущество — возможность нескольких представлений для одного текста: разные стили могут использоваться для разных устройств или ситуаций. Изменение одного стиля автоматически оказывает влияние на все ранее созданные тексты, без необходимости их изменения.
Стоит отметить, что принцип отделения разметки и внешнего представления, более универсален и может быть реализован, даже без использования поддерживающего его формата, такого как HTML. Например, сходных результатов можно достичь применяя Pandoc для конвертации из одного формата в множество других. Для каждого целевого формата, возможно задать отдельные файлы со стилями или шаблоны, даже если сам формат (такой как docx) не поддерживает их.
Итак, в текстологической работе следует сосредоточиться на содержании, а всю работу по внешнему виду, стилизации и конвертации текстов автоматизировать. Форматы направленные на воспроизводство печатной книги мало подходят для текстологии.
Элементы разметки
Наметив, в первом приближении способ разметки — с помощью текста, продолжим рассмотрение того что именно мы хотим разметить. С одной стороны точно нужно включить в результат работы все символы авторского текста, с другой нам не требуется сохранять цвет шрифта или ширину полей печатного издания. Между этими крайностями есть огромное количество вариантов. Формирование точного набора элементов необходимых для фиксации в разметке требует широкой, в том числе международной дискуссии. Далее мы представляем, скорее размышление по поводу необходимого или лишнего, чем готовое для использования руководство.
При обсуждении элементов разметки ещё раз стоит отметить проблему различения бумажного издания и авторского текста:
Не говоря о повсеместной неспособности организационно и технически отделить имитацию бумажного издания от воспроизведения авторского текста, то есть неспособности решить главный вопрос текстологии. Не говоря также о почти полном отсутствии попыток синтеза разметки бумажного издания и авторского текста («раздвоение единого...» и т. д) нужно отметить принципиальную невозможность (по политическим и экономическим причинам) выработать в рамках одного языка ориентиры текстологической работы. [5]
Бумажное издание (как в определённом смысле и рукопись) является только оболочкой, формой в которой выражен авторский замысел. Нет нужды отображать в разметке все аспекты бумаги, но в то же время нельзя и упустить что-то влияющие на авторский замысел.
Абзацы

Существую разные способы выделения абзацев в тексте, но они не влияют на его назначение — группировку предложений. Самый простой способ деления текста на абзацы — использование символов переноса строки.
Принудительный перенос
Отдельного вопроса заслуживает необходимость наличия в разметке возможности принудительного переноса. Принудительный перенос позволяет включить в один абзац несколько строк, это похоже, на элемент <br\> в HTML.
Некоторые форматы (например, fb2 принципиально отказываются от него, так как их авторы считают, что для выражения смысла должно быть достаточно абзацев, списков, и элементов для стихотворений.
Заголовки и подзаголовки

Необходима возможность разметки заголовков разных уровней и подзаголовков. Заголовки отображаются в оглавлении, а подзаголовки, обычно, нет.
Эпиграфы

Эпиграфы идут после заголовка и, обычно, выделяется бОльшим отступом.
Выделения в тексте (Акцент)


Акцент применяется для выделения отдельный слов или участков текста. Традиции выделений в тексте зависят от страны и меняются со временем. Сейчас чаще всего приходиться сталкиваться с курсивом и жирным шрифтом.

Разрядку стоит заменять на жирный шрифт, так как она не используется в современной типографике.
Есть и другие элементы, необходимость которых следует ещё обосновать: подчеркивание, зачёркивание, наклонный шрифт и др.
Цитаты

Для цитат, кроме самого текста, необходима ссылка на автора цитаты и на источник. Это позволит проводить автоматическую сверку цитат или переход к цитируемому произведению, о чём будет детальнее сказано далее.
Для цитат, ссылок на произведения в библиографическом списке и в примечаниях следует использовать формат совместимый с Citation Style Language. Это позволит автоматически подстраивать вывод ссылок по академическим правилам любой страны, университета или издания, а так же импортировать закладки в популярные библиографические менеджеры, такие как Zotero и Mendeley.
Принцип органического встраивания CSL в текстологическую работу требует дальнейшей проработки. Тесная интеграция с этой системой выглядит перспективной.
Изображения


Изображения можно хранить в виде файла, а в разметке только указывать ссылку на него, а можно кодировать прямо внутри текстового формата. Для изображений необходимо указание заголовка. В некоторых случаях рядом с изображением находится подпись или комментарий, их тоже было бы полезно отразить в разметке.
Подписи и описания изображений могут использоваться для автоматического построения указателя иллюстраций.
Схемы и графики
Кроме фотографий, в качестве изображений выступают разного рода схемы и графики. Их можно представить в виде изображений, но это не самый лучший способ. Мы получаем проблемы сходные с теми из-за которых пришлось отказаться от бинарных форматов. Предположим, на схеме имеется несколько подписей. Если это изображение, то для перевода на каждый язык переводчику необходимо будет его редактировать в графическом редакторе. Это трудозатратно и с большой вероятностью приведет к ухудшению качества изображения. Ещё одна важная сторона, растровые изображения теряют в качестве при масштабировании, что ухудшает возможности просмотра схем на разных устройствах. Кроме того, бинарный формат изображения не позволит в автоматическом режиме проверить и отобразить различия между переводом и оригиналом.
Выходом является использование векторной графики. В отличии от растровой, где изображение задано ограниченным набором точек, векторное изображение задается с помощью математических формул, оно не привязано к определённому разрешению и хорошо масштабируется. Для большинства случаев можно использовать популярный текстовый формат векторной графики SVG. То что он - текстовый, позволяет переводчику только изменить надписи, причем через любой текстовый редактор, как и для остального текста [6].
SVG позволяет нарисовать любое изображения и следовательно его возможности могут быть избыточны. Для более простых случаев можно использовать специализированные языки с тем же результатом: изображение будет задаваться с помощью текста, что облегчит перевод, сравнение и модификацию. Примеры таких языков: GraphViz и Mermaid.
Формулы


Ситуация с формулами сходна с со схемами и графиками — их удобнее всего отображать в виде текста. Это облегчает редактирование и перевод. Сейчас есть несколько подходящих для этого языков: MathML, AsciiMath и формулы на LaTeX.
Наиболее перспективным выглядит использовать LaTeX: его просто редактировать и есть хорошие средства для визуализации (MathJax и KaTeX).
Примечания и комментарии

Так как одна из задач текстологии — воспроизведение авторского понимания текста, необходима возможность деления примечаний на авторские и все остальные. Необходимость более глубокой детализации под вопросом, возможно, будет полезно выделение следующих типов примечаний: библиографическая ссылка, перевод слова, комментарий, примечание для переводчика. Возможно, необходимость такой детализации отпадёт при использовании концепции слоёв, описанной далее.
Примечания могут состоять из нескольких абзацев, разметка должна это учитывать. Для примечаний со ссылками на источники относится всё указанное касательно CSL в разделе про цитаты.
Номера страниц
Из-за того, что цитаты, предметные указатели и библиографические списки сейчас используют номера страниц, то при переводе книг в современный электронный вид полезно сохранять номера страниц печатного оригинала. Соответственно, для этого необходимы средства в разметке. Вероятно, это временная, вспомогательная, не всегда необходимая мера. В некотором смысле, номера страниц связывают авторский текст с его выражением в конкретном издании. Возможно, номера страниц больше полезны для рукописей, чем для печатных изданий.
Стихотворения

Из-за проблем с экспортом в другие форматы, каждую строку стихотворения неудобно отмечать абзацем, и она по сути им и не является. Логичной выглядит разметка строф и строк в стихотворении. Похожие элементы разметки poem, stanza, v реализованы в FB2.
Данный элемент разметки требует более детального исследования, так как есть сложные случаи, такие как стихи Владимира Маяковского.
Разделитель

Иногда, внутри одной главы абзацы разделяются на группы, без указания осмысленного заголовка. Для отображения этого потребуется отдельный элемент — разделитель.
Маркированные и нумерованные списки
Список состоит из последовательности абзацев. Списки бывают многоуровневые — один список является элементом другого списка.
Таблицы
Таблицы это один самых сложных элементов для разметки. Можно посоветовать размечать простые варианты текстом, а сложные варианты с использованием, упомянутого при обсуждении схем, формата векторной графики SVG.
Как и при обсуждении других элементов, цель в выделении авторского замысла, а не в фиксации той формы в которой он задан. Поэтому не всегда необходимо стремиться воспроизвести сложные элементы именно так как они были напечатаны в исходной книге. Вот элементы которые, вероятно, необходимо выражать в разметке:
- Непосредственно сама таблица — набор строк и столбцов;
- Заголовок таблицы (как для изображений);
- Шапка таблицы (выделенная строка);
- Подпись или комментарий к таблице;
- Объединение ячеек по столбцам и строкам.
В некоторых случаях может потребоваться добавлять внутрь ячеек другие элементы: абзацы, списки, изображения и др.
Блоки кода

В относительно современной литературе (например, книги Глушкова В. М.) встречаются примеры кода на языках программирования. Отдельное выделение таких блоков необходимо, так как они требуют особой обработки при экспорте из системы: шрифт с равной шириной букв, подсветка исходного кода, обязательное сохранение пробелов в том виде в котором они введены.
Другие элементы

Остаётся ещё ряд элементов разметки необходимых для специализированных изданий, например, индексы в переводах с греческого.
Для некоторых ситуаций можно подобрать уже готовые языки текстовой разметки, например, для нот.
На первом этапе, разумно включить в основную разметку элементы покрывающие подавляющие большую часть случаев, а для остального предусмотреть возможности для расширения.
Экранирование элементов разметки
Так как элементы разметки задаются внутри текста символами обычного текста, то иногда может потребоваться ввести эти же элементы именно как текст, а не как элементы разметки. При правильно выбранном способе разметки это редкая ситуация, но её нужно предусмотреть. Один из вариантов это использование экранирующего символа.
Например, мы решили выделять курсивный текст символом *. Чтобы ввести этот символ в текст не как элемент разметки, перед ним записывается другой специально определённый экранирующий символ, например, \. Если же нам нужно ввести сам экранирующий символ, то просто вводим его два раза \\.
Вложенность элементов разметки
Все описанные выше элементы не всегда просто следуют друг за другом, но часто вкладываются друг в друга. Разметка должна позволять адекватно задать эту вложенность. Например, цитата или примечания может содержать несколько абзацев, а абзац может содержать внутри себя выделения курсивом или жирным шрифтом.
Эквивалентность текстовых форматов
Определив, в первом приближении, что мы хотим разметить в тексте, становится понятно, что полностью подходящего по всем параметрам языка разметки ещё не существует. Но, может быть, существует близкий, в достаточной мере подходящий чтобы начать с него. Для сравнения нам требуются какие-то критерии, чтобы их выработать остановимся детальнее на принципах по которым происходит машинная обработка текста.
Суть любой разметки сводится к описанию формальной грамматики — способа задать некоторые правила, по которым можно однозначно определить является ли данный текст правильным с точки зрения данной грамматики или нет. Для того чтобы это проверить рассмотрим один из способов анализа двух фрагментов текста: в разметке Markdown и в HTML. Пример будет немного упрощен, но он позволит увидеть наиболее важные стороны рассматриваемого процесса.
Фрагмент в Markdown:
# Пример
Абзац с **выделенным** текстом
Фрагмент в HTML:
<h1>Пример</h1>
<p>Абзац с <strong>выделенным</strong> текстом</p>
Следуя принципу деления на уровни абстракции, программа обычно делит разбор данного текста на два этапа: лексический анализ и синтаксический анализ.
При лексическом анализе на вход подаётся последовательность символов, а на выходе получается набор лексем. Лексемами являются логически сгруппированные наборы символов с присваиванием им определённого типа, примерно, как буквы в одном слове. Для наших примеров последовательности токенов могут быть следующие:
Фрагмент в Markdown:
- Заголовок ("#")
- Текст ("Пример")
- Перевод строки
- Перевод строки
- Текст ("Абзац с ")
- Жирный шрифт ("**")
- Текст ("выделенным")
- Жирный шрифт ("**")
- Текст (" текстом")
Фрагмент в HTML:
- Начало заголовка ("<h1>")
- Текст ("Пример")
- Окончание заголовка ("</h1>")
- Начало абзаца ("<p>")
- Текст ("Абзац с ")
- Начало выделения жирным ("<strong>")
- Текст ("выделенным")
- Окончание выделения жирным ("</strong>")
- Текст (" текстом")
- Окончание абзаца ("</p>")
Отметим важную особенность: последовательности символов для токенов могут быть любые, если они подчиняются формальным правилам. Для Markdown перевод строки можно считать полноценным токеном, а HTML игнорирует переводы строки и они не влияют на результат [7].
После лексического анализа последовательности токенов передаются синтаксическому анализатору. Он уже не работает с отдельными символами, его интересуют только типы токенов. Во время фазы синтаксического анализа одновременно происходит проверка правил разметки (например, чтобы внутри одного заголовка не добавили второй) и формирование абстрактного синтаксического дерева (AST) — структуры с которой далее и будет работать программа. Синтаксическое дерево состоит из связанный друг с другом узлов. Есть корневой узел — документ, и дочерние от него узлы, которые так же могут содержать свои дочерние узлы.
Рассмотрим правила по которым может быть сформировано AST для Markdown.
- Элемент Заголовок начинается с токена Заголовок и завершается токеном Перевод строки;
- Отдельный токен Перевод строки игнорируется;
- Элемент Абзац начинается с токена Текст и завершается токеном Перевод строки или концом документа;
- Элемент Жирный шрифт начинается с токена Жирный шрифт и оканчивается токеном Жирный шрифт.
При применении этих правил получаем следующее AST:
Документ
|- Заголовок
|- Абзац
|- Жирный текст
Теперь рассмотрим возможные правила для HTML:
- Элемент Заголовок начинается с токена Начало заголовка и оканчивается токеном Окончание заголовка;
- Элемент Абзац начинается с токена Начало абзаца и оканчивается токеном Окончание абзаца;
- Элемент Жирный шрифт начинается с токена Начало выделения жирным и оканчивается токеном Окончание выделения жирным.
Самое важное, что при применении этих правил мы получим то AST аналогичное тому что получили при разборе примера на Markdown! Информация об исходной разметке была утрачена при переходе к представлению текста внутри системы. Далее AST может быть преобразовано в другой вид, отображено на экране (естественно в удобном для чтения или другой работы виде) или использовано для генерации электронной книге. Машине не важно как именно, какими символами была задана разметка, а важно только что она выражает.
Тяжелая и лёгкая текстовая разметка
Рассмотрим детальнее для чего нам нужна разметка. Нам необходимо выделить в тексте все элементы, важные для отражения авторского замысла. Как мы убедились выше, для машины нет особого значения в какой форме, какими именно символами будет производиться разметка. Но если это не важно для машины, то это важно для человека. Человеку должно быть просто и удобно
- Вводить текст в выбранной разметке;
- Читать текст в выбранной разметке.
Рассмотрим два варианта, текст в формате DocBook предназначенный для разметки документов и аналогичный текст в формате Markdown.
Текст в DocBook:
<?xml version="1.0" encoding="UTF-8"?>
<book xml:id="simple_book" xmlns="http://docbook.org/ns/docbook" version="5.0">
<title>Very simple book</title>
<chapter xml:id="chapter_1">
<title>Chapter 1</title>
<para>Hello world!</para>
<para>I hope that your day is proceeding <emphasis>splendidly</emphasis>!</para>
</chapter>
<chapter xml:id="chapter_2">
<title>Chapter 2</title>
<para>Hello again, world!</para>
</chapter>
</book>
Текст в Markdown:
# Very simple book
## Chapter 1
Hello world!
I hope that your day is proceeding **splendidly**!
## Chapter 2
Hello again, world!
Очевидно, что второй вариант гораздо проще для чтения и редактирования, даже если применить такой примитивный критерий как подсчет количества символов. Рассмотрим детальнее их различия.
DocBook относится к языкам разметки основанным на XML. XML определяет базовые правила по которым должна происходить разметка документа. Упрощенно они сводятся к тому, что
- Разметка состоит из элементов;
- Каждый элемент начинается с открывающего тега и оканчивается закрывающим, между которыми находиться содержимое элементов. У каждого тега есть имя, например <p>Абзац</p>;
- Элементы могут вкладываться друг в друга.
Какие именно элементы могут появиться в разметке и как они могут соотноситься друг с другом определяется уже конкретным языком разметки, таким как DocBook или HTML. Языки разметки основанные на XML хорошо подходят для машинной обработки, но только относительно понятно и удобны для чтения человеком. Документы на XML-подобных языках разметки редко редактируются напрямую, а обычно используются специальные программы, которые предоставляют пользователю интерфейс для просмотра или редактирования. Естественно, для каждого вида XML-документов требуется своя программа: для DocBook одна, для DITA] вторая, а для FB2 третья. Существуют универсальные XML-редакторы, но из-за своей универсальности они не могут отразить и использовать специфику определённого формата.
Противоречие необходимости редактировать и читать текст с возможностью его машинной обработки разрешилось появлением и развитием облегчённых языков разметки. Они позволяют выразить достаточно элементов, но в то же время текст на них минимально отличается от простого текста написанного вообще без разметки. Одновременно с этим повышается доступность: для редактирования и чтения файла подойдёт любой простейший текстовый редактор, а если нужны какие-то дополнительные возможности то для них тоже есть WYSIWYG-редакторы.
Выбор облегченного языка разметки логичен для экономии трудовых ресурсов и удобства вычитки. Внутри системы текст всё равно будет находиться в виде AST, реляционных таблиц или каком-то другом, но когда он подготавливается, читается и редактируется людьми, логично выбрать формат удобный именно для людей.
В силу особенностей текстологических задач, обозначенных выше в описании необходимых элементов разметки, любой из выбранных форматов нужно будет расширять: вводить свои элементы разметки, редактировать или убирать существующие. Так же можно комбинировать удачные подходы из разных языков разметки. Для начала работ, если никаких технических средств ещё не создано, эффективнее всего взять один самых популярных форматов, для работы с которым уже создано много технических средств. К таким форматам можно отнести: варианты Markdown GitHub Flavored Markdown и MultiMarkwon, reStructuredText, AsciiDoc. Особого внимания заслуживает Org-mode. Это далеко не полный список, например, можно рассмотреть список языков разметки со страницы популярной утилиты конвертации документов между разными форматами Pandoc.
В итоге, для разметки следует использовать свой, разработанный специально для этой задачи, формат основанный на языках облегчённой разметки текстов.
Структура данных и её реализация
Мы определились с направлениям того как хранить текст,— с использованием кодировки основанной на Unicode, и с тем как размечать элементы авторского замысла не являющиеся просто текстом,— с использованием языка основанного на облегчённом языке текстовой разметки. Но это относится только к первой задаче текстологии — установление авторского текста, для второй задачи — организация и композиция текстов, этого уже недостаточно.
Коллекция произведений, даже одного автора, не является одним текстом. Кроме того, для исследовательских целей, есть необходимость хранить разные варианты одного и того же текста, напечатанные в разных годах, в разных издания и т. п. Отдельной, но тесно связанной, задачей идёт хранение переводов. Огромные возможности предоставляемые современной техникой, такие как поиск или сравнение, могут быть использованы только если тексты хранятся специфическим образом.
Чтобы продуктивно обсуждать способ хранения текстов, необходимо рассмотреть идею различия структуры данных и реализации. Рассмотрим пример следующей структуры данных
- Автор имеет Имя, Фамилию, Отчество и Дату рождения;
- Произведение имеет Название и Дату публикации и Текст произведения;
- Произведение всегда написано только одним Автором;
- Печатное издание имеет Название, Название издательства и Дату публикации;
- Печатное издание может включать одну или несколько Произведений, а одно Произведение может находиться в нескольких Печатных изданиях.
В этой модели обозначены три сущности: Автор, Произведение и Печатное издание. Кроме этого указаны свойства сущностей и связи между ними. По сути это ER-модель — концептуальная схема предметной области, в данном случае текстологии. Самое важное что эта модель никак ничего не говорит о способе её реализации, она только описывает предметную область. Мы можем даже использовать эту модель и вести текстологическую картотеку используя бумагу и несколько шкафов, но нас, конечно, больше интересует цифровой формат, поэтому сосредоточимся на нём.
Выбранная модель данных может быть реализована с помощью следующих правил:
- Для каждого Автора создаётся отдельный каталог;
- Произведения и Печатные издания хранятся в отдельных файлах в каталогах автора;
- Дополнительная информация об авторе храниться в файле Автор.txt в каталоге автора.
Текстологическая база данных
|- Автор01
| |- Автор.txt
| |- Произведение01.txt
| |- Произведение02.txt
| |- Печатное издание01.txt
|
|- Автор02
|- Автор.txt
|- Произведение01.txt
|- Печатное издание01.txt
Пример файла с описанием автора:
name: Иванов Иван Иванович
birthday: 01.10.1910
Пример файла, описания печатного издания, в котором перечисляются произведения, выходящие в печатное издание:
Произведение1
Произведение2
Произведение3
То что мы описали, это один из способов реализации модели данных, в этом случае с использованием файлов и каталогов. Рассмотрим второй вариант реализации, на основе реляционной базы данных:
create table authors (
first_name text,
last_name text,
middle_name text,
birthday date
);
create table works (
name text,
publish_date date,
work_text text
);
create table books (
name text,
publisher text,
publish_date date
);
create table works_books (
author_id text,
work_id text
);
alter table works add foreign key (author_id) references authors (author_id);
alter table books_works add foreign key (book_id) references books (book_id);
alter table books_works add foreign key (work_id) references works (work_id);
Обе реализации сильно отличаются, и имеют свои преимущества и недостатки. К примеру, внесение изменений в файлы может быть произведено в любом текстовом редакторе, а для использование базы данных понадобиться установка СУБД. А одно из преимуществе базы данных — автоматический контроль корректности данных, например, чтобы нельзя было ввести Произведение для несуществующего Автора. Главное отметить что обе реализации основаны на одной и той же модели данных и в этом отношении они эквивалентны. Когда мы обсуждаем структуру данных для текстологической работы нам следует сосредоточиться именно на модели, а не на её реализации. Завязка на реализацию значительно ограничивает возможности массового использования данной модели: одна группа может обладать технической компетенцией для работы с базой данных, а другая нет. Технические компетенции группы также могут быть привязаны к конкретной СУБД, или же опираться на другие технологии. Задачи группы могут включать в себя необходимость использования преимуществ СУБД, а могут не включать. Концентрации на модели данных вместо реализации, позволяет не учитывать все эти детали, а сосредоточиться на самом важном и общем для текстологической работы.
Другим примером структуры данных является AST, обсуждаемое выше в разделе про текстовые форматы, а модель базы данных для текстологической работы представляет собой пример реализации — она специфична для определённой реляционной базы данных (PostgreSQL).
Отличия модели данных для внутреннего использования и для обмена
Рассмотрим детальнее модель данных для чего нам необходимо составить. Модель данных данных предназначена для хранения данных, нужно указать какие произведения есть у автора, когда они издавались, были ли соавторы и т. д. То что мы намерены хранить определяет свойства модели. Но модель не просто что-то хранит, мы намерены использовать её: производить поиск, составлять разные издания, редактировать опечатки и производить другую работу. Свойства модели так же зависят от наших целей, как от самих данных.
К примеру, мы можем просто расширить язык разметки, обсуждаемый выше. Ввести в него возможность указания авторов, печатных изданий и всё остальной информации. Но в этом случае исчезнет основное преимущество легкого языка разметки — простота редактирования, а каких-то особых преимуществ мы не получим.
Другие примеры. Если мы хотим хранить несколько версий текстов одного автора для изучения развития авторской мысли отражённой в корректировках текста, то нам необходимо выделить в отдельную сущность модели — версия текста. А если у небольшого коллектива стоит задача перевода нескольких произведений Ленина на национальный язык, то какой-то необходимости учитывать версию текста у них нет, для этой задачи вполне достаточно одной версии.
Учитывая разницу между целями и возможностями разных групп, занятых текстологической работой мы не можем сформировать единый набор требований для модели данных, ведь модель отчасти и основывается на возможностях и целях группы. Оставить выбор модели данных на произвол каждой группы тоже нельзя — это противоречит задаче глобального обмена результатами текстологической работы, совместимости этих результатов. Но ведь мы и можем сконцентрироваться именно на этом — на модели данных для обмена информацией, вместо построения модели подходящей для целей и задач только некоторых групп.
Рассмотрим один из международных стандартов в области здравоохранения HL7 версии 4 — FHIR. Документооборот в области здравоохранения различается в разных странах, округах одной страны и даже в разных медицинских учреждениях. Разные профили оказания медицинской помощи, размер учреждений, законодательство, разные поставщики программного обеспечения — всё накладывает ограничения, которые приводят к несовместимости медицинских данных зафиксированных в разных медицинских организациях, не смотря на то, что суть работы, в значительной мере совпадает: врачи делают осмотры, хирурги проводят операции, а в лаборатории производятся лабораторные исследования.
В противовес раздробленности системы здравоохранения, пациентам нужно иметь единую электронную медицинскую карту, независимо в каком учреждении они проходили лечение, а государственным службам получать общие статистические показатели по стране. Из этого противотечения и появляются попытки создания международных стандартов, которые способны обеспечить передачу и использование данных от разных поставщиков. Стандарт FHIR подразумевает разные способы использования: можно посмотреть его описание и получить идеи и информации для упрощения разработки системы, можно использовать этот формат для обмена данными между другими системами — предоставлять данные в формате FHIT во вне и принимать данные в этом формате внутрь системы, а можно реализовать систему полностью на основе этого формата, когда внутренняя структура будет соответствовать стандарту. Разработчики, в зависимости от целей и возможностей выбирают подход для конкретного проекта.
Ситуация с текстологической работой имеет сходные моменты с описанным примером. Описанная модель данных (формат, стандарт, структура данных) может помочь в обмене результатами между разными группами, или как минимум повысить совместимость этих результатов.
Итак, наиболее перспективно для международного сотрудничества выглядит разработка стандарта для обмена текстологической информацией для повышения совместимости результатов работы.
Отделение формата от программы
Не вызывает сомнений, что для текстологической работы нужно будет разработать специальные программные средства упрощающие и облегчающие эту работу, но разрабатываемый формат не должен привязываться к какому-то конкретному средству реализующему этого формат. Цель формата — как можно большая универсальность и независимость от специфики отдельных средств.
Описанный стандарт позволяет независимо разрабатывать разные средства, под разные задачи, следуя философии Unix: одна программа делает только одно действие, но делает его хорошо и совместима с другими программами. Например, можно разработать отдельное средство для конвертации из нашего формата в PDF, FB2, ODF и другие форматы. Другое же средство может отображать библиотеку и отдельные книги в виде сайта. Причем, каждое из этих средств может реализовываться на разных технологиях и с разными возможностями.
Готовые текстологические базы данных могут использовать адаптеры для импорта и экспорта данных в общем формате. А будущие разработки, если это совпадёт с целями группы, могут разработать базу данных более совместимую со стандартом.
Элементы модели данных
Так же как и с разметкой, появляется два вопроса: что должно входит в модель данных и как оформлять модель данных?
При выборе элементов за основу мы можем взять модель, реализованную в виде FZR-схемы. Приведем примерный список сущностей, для включения в стандарт:
- Автор
- Произведение
- Версия произведения
- Абзац
- Печатный материал
- Страница
- Серия
- Издание
- Перевод
- Язык
- Переводчик
- Издательство
- Страница фотокопии
- Фрагмент страницы фотокопии
Список элементов, их свойств и связей между ними требует дальнейшей проработки, выходящей за рамки данного обзора.
Способы оформления стандарта
Рассмотрим как должен выглядеть стандарт. По тем же причинам, что указаны для разметки, наиболее удобен выбор текстового формата. Отличие от разметки, предназначенной для облегчения чтения и редактирования текстов, формат для обмена больше предназначается для машины, чем для человека. Редактирование данных для обмена вручную возможно, но чаще будет производиться сделанными специально для этого программные средствами.
Таким образом, формат может быть основан на XML или сходных технологиях. Основное требование для машиночитаемого формата это формальное описание. Оно позволяет проверить соответствуют ли данный текст заданному стандартом формату или нет. Описанный выше, пример ER-модели недостаточно удобен для этих целей и подходит скорее для обсуждения и проработки концепции между людьми. В идеальном случае, формат должен быть независим от используемого способа разметки и позволять равнозначно использовать XML и JSON.
Выбор конкретного способа формальной разметки требует дальнейшей проработки. Можно рассмотреть, РБНФ для разметки, XSD и JSON Schema как валидаторы для XML и JSON, модель RDF. Вероятно, для описания семантики, как и для разметки текста, так и для структуры модели данных понадобится обычное текстовое описание. Проще всего начать именно с него.
Комментирование
Третья задача текстологии является комментирование текстов. Комментарии могут быть разного типа: авторские комментарии, примечания переводчика, редактора и др. В разных типах издания подходящими будут разные типы комментариев. Некоторые издания могут быть вообще, без комментариев. Но авторский текст, установленный на данный момент, всегда будет тем же самым, во всех изданиях.
Способы внесения комментариев в текст требуют технической проработки. Наиболее перспективной выглядит идея о разделении авторского текста и комментариев — концепция слоёв. Авторский текст остаётся неизменным, но поверх него можно добавлять новую информацию.
Вариант реализации, когда в тексте ставиться ссылка на примечание
[^54]
уже нарушает авторский текст. Один из способов этого избежать это хранить в самом примечании позицию куда его нужно вставить. Одна из проблем — это изменение авторского текста, например, исправление опечаток. После изменения символов позиции слоёв могут нарушиться. Но эта проблема может быть решена усложнение автоматической процедуры слияния с новой версией, хотя, такой алгоритм требует исследования.
Полное отделение слоёв позволит неограниченно добавлять и использовать их для любых целей.
Объединение результатов работы
Разрабатываемый формат обмена должен быть направлен на упрощение объединения результатов текстологической работы раздельных групп. Основные направления объединения:переводы и совместное редактирование.
Объединение не означает размещение на одном сервере или в одной базе данных, хотя и такой способ возможен, а потенциальную совместимость работ. Рассмотрим пример: если ПСС Ленина будет переведён на украинский и белорусский языки, то между ними должна быть возможность автоматически сопоставить переводы друг другу. Сопоставить переводы означает определить какой абзац на украинском соответствует данному абзацу на белорусском. Для этой цели формат должен позволять ссылаться на абзацы, а для этого у абзаца должен быть идентификатор. Кроме абзаца такой же идентификатор необходим у любого блока текста: заголовка, изображения и т. д.
Недостатки использования в качестве абзаца порядкового номера уже детально разобраны, основный из них — при изменении текста, порядок абзацев может измениться, а следовательно все сопоставления сломаются. Один из вариантов решения — использовать GUID для всех идентификаторов. В этом случае, При любом изменении абзацев нужно будет отредактировать только сопоставление для измененных абзацев.
Проблема с идентификаторами только одна из комплекса проблем которые необходимо решить, чтобы формат позволял легко совмещать различные работы. Выработка решений будет производиться совместно с разработкой формата. Сейчас можно только наметить проблемы, которые видно сразу:
- Поддержка разных версий текста, так чтобы сопоставления для переводов, комментарии и другие элементы не было необходимо;
- Необходимость общих справочников: языков, авторов, произведений. В некоторых случаях можно обойтись готовыми решениями, например, ISO 639 для справочника языков.
Текстология как мышление человечества
Мы кратко разобрали особенности выполнения текстологических задач в цифровом формате: сохранение авторского текста, организация текстов и комментирование. Но с появлением новых технологий масштабность возникают новые, гораздо более масштабные задачи.
Технические средства, как тесно связанную с другими часть человеческой культуры, можно считать материальным субстратом мышления, или «общественным мозгом». Современные научные исследования не могут производиться в одиночку, а часто производятся гигантскими коллективами людей. Для эффективной работы таких коллективов требуется современное техническое оснащение:
В развитии человеческого общества неизбежно наступает момент, когда резервы традиционных приемов совершенствования управления — организация и социально-экономические механизмы — оказываются исчерпанными. Ведь пропускная способность человеческого мозга, как преобразователя информации, хотя и велика, но ограничена. В своей книге «Основы безбумажной информатики» Глушков называет такую ситуацию вторым информационным барьером (Первым информационным барьером называется порог сложности управления системой, превосходящей возможности одного человека). Для преодоления второго информационного барьера человек должен большинство функций по преобразованию информации и управлению передать компьютеру. [8]
На базе размеченных текстов может быть создана высокоуровневая информационная система или даже экосистема информационных систем. Попробуем обозначить некоторые перспективные возможности.
Свобода изменения внешнего вида. Для отображения работ может применяться полноценное веб-приложение, с тонкой настройкой внешнего вида под задачи пользователя. Если нужен только авторский текст, то останется только он, а если потребуется отобразить номера страниц из печатного варианта или текстологические комментарии, то это будет сделано включением соответствующих опций. Такие вещи как настройка шрифта, цвета фона и других параметров не представляют никакой сложности для современных браузеров даже сейчас.
Просмотр переводов и оригинала. Для каждого фрагмента можно посмотреть перевод на заданном языке, или оригинал, если пользователь смотрит перевод, а от оригинала перейти к фотокопии книги или даже к исходной рукописи.
Автоматизация поиска и сравнения. Не трудно организовать поиск с учетом морфологии слов по всему набору произведений, с учётом заданных фильтров: по автору, серии и любых других. Для исследований может быть полезна автоматизация поиска и отображение в удобном виде различия между разными редакциями текста или в разных вариантах перевода. Могут параллельно существовать тексты с современной и устаревшей грамматикой.
Информационная система может позволять хранить и комментировать цитаты из различных произведений. Причем для коллективной работы могут создаваться целые информационные слои с комментариями, дополнительными примерами или разъяснениями. Подобным же образом можно связать критическую работу с критикуемым материалом, или текст учебного пособия с текстами первоисточников. Внешний вид может позволять включать, отключать разные слои, или выбирать необходимую степень их детализации.
При достаточной разметке цитат их можно будет автоматически проверять на корректность. Возможен переход в один клик к фрагменту в цитируемом произведении, а на основе ссылок можно строить графы связей работ или авторов.
Указатели могут строиться как автоматически, так и вручную, главное чтобы можно было указать прямой идентификатор заданного блока текста. При определённом развитии системы указатели, как и многие другие элементы, могут наполняться коллективно по принципам wiki-технологий. То же относиться к поиску и исправлению опечаток.
Широкая интеграция со сходными по назначению системами, такими как Mendeley, Zotero, Qiqqa, является ещё одним из важных направлений работы.
При коллективном развитии автоматизации текстологической работы, наверняка, появятся и другие, намного лучшие идеи и возможности, чем представленные выше.
Выводы
Кратко отметим основные направления по которым, мы считаем, следует вести дальнейшие исследования и как можно более широкое обсуждение.
Разработка международных критериев и формата для разметки текстов. Разработка принципов разметки, выбор и описание элементов разметки, формальное описание разметки;
Разработка стандарта для обмена текстологической информацией, формирование списка элементов, их свойств и связей. Формальное описание стандарта;
Составление списка справочников, необходимых для обмена текстологической информацией, их наполнение и публикация.
С. А. Рейсер. Основы текстологии, 1978. стр. 11. ↩︎
С. А. Рейсер. Основы текстологии, 1978. стр. 33. ↩︎
При детализации всё оказывается несколько сложнее, есть кодовые точки без символа, а некоторые кодовые точки группируются в один символ. ↩︎
С. А. Рейсер. Основы текстологии, 1978. стр. 23. ↩︎
Что не так с текстологией и как исправить ситуацию? Часть VI К оценке текстологического плана коллектива «Заря». ↩︎
Возможны исключения и из-за разной длины надписей на разных языках потребуется изменение изображения, но это минимальные изменения и они проще чем в редакторе растровых изображений. ↩︎
за исключением особых случаев вроде элемента <pre>. ↩︎
Управление научно-техническим прогрессом: концепция В. М. Глушкова. ↩︎