Фотокопия книги и текст книги
27.09.2025
Бумажная книга неразрывно связывает текст и физическое тело издания. При оцифровке текст отрывается от отсканированных страниц. Этот разрыв позволяет задать вопрос: в каком виде может существовать связь между электронным текстом и фотокопией, и зачем она нужна.
Под книгой далее подразумевается электронная книга — текст в любом облегчённом формате разметки или данные, хранящиеся в структурированной базе. Под сканом — набор изображений бумажной книги в любом формате: отдельные изображения, PDF, DjVu и др.
Виды связи
Связь текста электронной книги со сканом может быть реализована с разной степенью детализации. Рассмотрим возможные варианты.
Отсутствие связи
Если для текста книги точно неизвестно из какого издания он взят, или известно издание, но его скан недоступен, можно считать, что связь между электронной книгой и сканом отсутствует.
При отсутствии скана невозможно быстро проверить подозрительное место на опечатку. В общем случае скан служит дополнительным подтверждением того, что текст не искажён. Если скана нет, подлинность цифрового текста основывается только на авторитете источника, откуда он получен.
Файловая связь
Если у вас есть электронная книга и её скан, например, в виде двух отдельных файлов, — это уже второй тип связи. Главное преимущество такого подхода — минимальные затраты на реализацию. Достаточно просто хранить два файла: текст и скан.
Недостаток в том, что связь слишком общая. Сравнить конкретный фрагмент текста с соответствующим участком скана приходится вручную: найти нужную страницу, затем — нужный абзац. Это трудоёмко и неудобно.
Связь по страницам
Сканы, как правило, состоят из изображений отдельных страниц. Электронная книга по умолчанию не делится на страницы, но такую разбивку можно добавить — с помощью специальных тегов (в лёгких форматах разметки) или структурной организации (если книга хранится в базе данных).
Когда и текст, и скан разделены по страницам, пользователь может, например, кликнуть на номер страницы и сразу увидеть её изображение. Даже без интерактивного интерфейса номер страницы помогает быстрее сопоставить текст и скан.
Такая связь используется в инструментах для вычитки, например, в Викитеке и Проекте Гутенберг.
Связь блока документа и фрагмента скана
Более сложный уровень — привязка отдельных блоков (абзацев, заголовков, таблиц) к соответствующим фрагментам скана. Такой подход применяется в системах OCR: перед распознаванием скан разделяют на зоны — текст, изображения, таблицы и т. д. Это повышает точность распознавания.
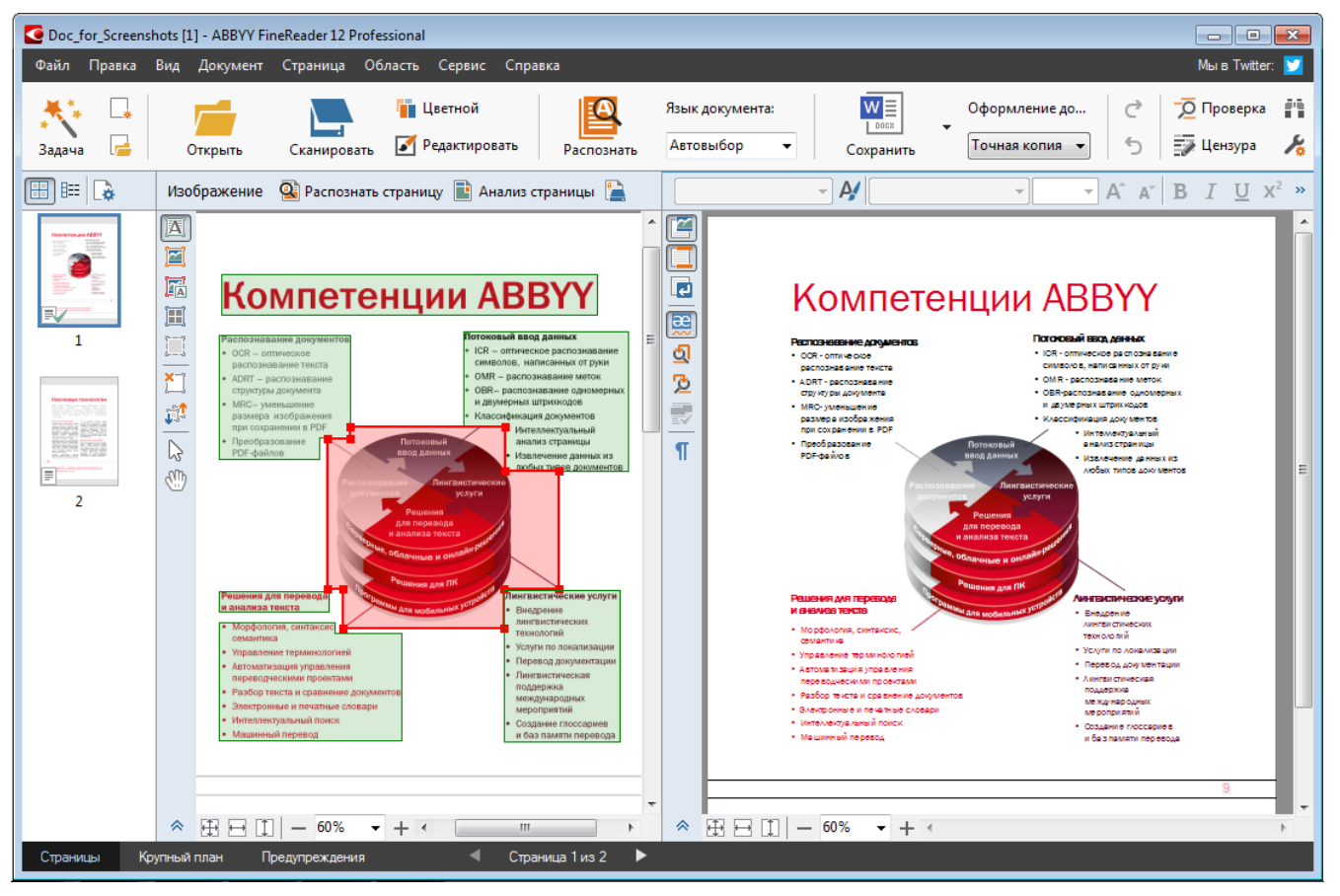
После завершения OCR такая разметка, обычно, не сохраняется. Хотя она могла бы пригодиться позже — например, для быстрой проверки опечаток.
Чтобы реализовать такую связь, нужно хранить параметры фрагментов: обычно достаточно прямоугольников, заданных координатами левого верхнего угла, шириной и высотой. Желательно также указывать тип фрагмента — текст, изображение и т. п., хотя это не обязательно.
Каждый фрагмент скана связывают с элементом книги — абзацем, таблицей, иллюстрацией. Для этого элементы должны иметь уникальные идентификаторы. Это могут быть независимые идентификаторы (например, GUID) или зависящие от содержания (хеш, порядковый номер). У каждого способа есть свои плюсы и минусы.
Текстовые файлы в облегчённой разметке плохо подходят для такой связи. Для нумерации страниц тегов достаточно — они не мешают чтению и легко добавляются. Но введение идентификаторов блоков и координат фрагментов уничтожает все преимущества простой разметки. Более того, редактирование координат требует специализированного ПО — обычного текстового редактора недостаточно.
Таким образом, эффективная реализация связи между блоками документа и фрагментами скана возможна либо через базу данных, либо через сложный формат хранения. В любом случае требуется специализированное программное обеспечение для редактирования и просмотра.
Автоматическая разметка фрагментов выполняется современными OCR-системами, но всё равно требует ручной корректировки. Создание такой связи остаётся трудоёмким процессом.
Связь слова и фрагмента скана
Наиболее детализированный уровень — привязка каждого слова к его местоположению на скане. Такой подход используется в OCR-форматах, например, в hOCR. hOCR — это HTML с добавленной информацией о координатах каждого слова.
Пример части документа в формате hOCR:
<p title="bbox 147 706 1316 1898" class="ocr_par" id="par_1_3">
<span title="baseline 0.002 -11; bbox 191 708 1315 750; x_ascenders 10.407609; x_descenders 10.221519; x_size 42.098957" class="ocr_line" id="line_1_4">
<span title="bbox 191 708 382 747; x_fsize 10; x_wconf 87" class="ocrx_word" id="word_1_13" lang="ru_RU">Индивиды,</span>
<span title="bbox 422 718 674 750; x_fsize 10; x_wconf 95" class="ocrx_word" id="word_1_14" lang="ru_RU">производящие</span>
<span title="bbox 714 719 731 739; x_fsize 10; x_wconf 95" class="ocrx_word" id="word_1_15" lang="ru_RU">в</span>
<span title="bbox 772 710 941 747; x_fsize 10; x_wconf 93" class="ocrx_word" id="word_1_16" lang="ru_RU">обществе,</span>
<span title="bbox 957 727 997 731; x_fsize 10; x_wconf 91" class="ocrx_word" id="word_1_17" lang="ru_RU">—</span>
<span title="bbox 1009 719 1028 741; x_fsize 10; x_wconf 72" class="ocrx_word" id="word_1_18" lang="ru_RU">а</span>
<span title="bbox 1050 718 1315 748; x_fsize 10; x_wconf 96" class="ocrx_word" id="word_1_19" lang="ru_RU">следовательно,</span>
</span>
Текстовый слой в PDF
Способ, близкий к hOCR, применяется при создании текстового слоя в PDF. По сути, это промежуточный вариант между полноценной электронной книгой и набором фотокопий.
Текстовый слой добавляет удобства: позволяет искать текст и копировать его. Однако эти функции работают неидеально. Поиск часто не справляется с фразами, переходящими на следующую строку. Копирование тоже может давать сбои. Кроме того, в текстовом слое теряется форматирование — курсив, жирный шрифт, разрядка и другие стили.
Текстовый слой обычно создаётся автоматически и редко проходит вычитку из-за высокой трудоёмкости. Поэтому он часто содержит ошибки.
PDF со сканом и текстовым слоем уступает полноценной электронной книге: ограничен поиск, сложнее конвертация, нужны специальные программы для открытия, большой объём хранения.
Тем не менее, такие PDF полезны — зачастую выбор стоит не между электронной книгой и сканом, а между просто сканом и сканом с текстовым слоем. Недостатки в основном технические. Возможно, в будущих форматах они будут решены и сканы с текстовым слоем станут удобнее.
Зачем может быть нужна связь со сканом
Прежде всего, связь фотокопии с электронной книгой важна на этапах оцифровки и вычитки. Об этом свидетельствуют примеры выше.
После оцифровки такая связь помогает проверять корректность текста. Здесь выделяют два аспекта: проверка на опечатки и проверка подлинности.
Проверка на опечатки: читатель кликает на подозрительное место — и сразу видит соответствующий фрагмент скана. Легко сравнить и исправить ошибку.
Проверка подлинности: скан даёт возможность убедиться, что текст не был намеренно изменён. Это похоже на принцип открытого исходного кода: не каждый проверяет, но возможность есть. Связь со сканом предоставляет аналогичную гарантию для оцифрованного текста. Впрочем, скан тоже можно подделать — правда, это сложнее. Поэтому нельзя говорить, что связь со сканом полностью решает проблему подлинности.
Наиболее полезной связь со сканом выглядит для рукописей и сходных сними уникальных произведений. В то же время издания старых книг тоже можно считать уникальными наравне с рукописями.
Недостатки связи со сканом
Связь со сканом полезна при оцифровке, но её поддержка в дальнейшем добавляет сложностей. Например, если появляется скан лучшего качества, старые координаты фрагментов становятся неверными — их нужно проверять или переразмечать.
Даже без смены сканов, разработка инструментов для редактирования и отображения таких связей требует значительных усилий. Простая привязка по страницам используется в ряде систем, но более сложные уровни связи встречаются в основном только в специализированных OCR-инструментах. Их отсутствие в массовых продуктах может означать, что спрос на них невелик или не оправдывает затрат.
Возможно, развитие ИИ позволит отказаться от жёсткой привязки. Нейросеть сможет находить нужный фрагмент на скане в реальном времени — тогда предварительная разметка и хранение координат и даже номеров страниц станут ненужными.
Книга и бумажная книга
Проблема сопоставления текста и скана — частный случай более общей ситуации. Один и тот же текст может существовать в разных изданиях: с разным оформлением, форматом, разбивкой на страницы. Тем не менее, содержание совпадает. С этой точки зрения, почему вообще важно привязывать текст именно к этому изданию? Ведь оцифровали его скорее случайно — могли бы и другое.
Однако в научной литературе издания могут отличаться существенно: редакционные правки, комментарии, примечания. Эти различия сами становятся предметом исследования. В таких случаях полезны и тексты, и сканы всех изданий.
Проблема сопоставления скана и текста существует потому, что старые книги изначально были бумажными и только сейчас переходят в цифровую форму. Современные книги чаще рождаются в цифровой форме. Необходимость распознавания скана современной книги исходит из юридических ограничений на распространение оригинальных цифровых версий.
По мере роста доли изначально цифровых книг проблема привязки к скану будет постепенно терять актуальность.
Формат, размер шрифта, поля, отступы — всё это характеристики бумажной книги, а не самой книги как текста. Даже такие устоявшиеся элементы, как нумерация страниц, используются для цитирования, но являются атавизмами в контексте полноценной цифровой книги.
Однако не всякая книга — это только текст. Изображения, компоновка, вёрстка и другие визуальные элементы теряются, когда книга превращается в последовательность символов с минимальной разметкой. Как решить эту проблему — покажет будущее цифровой книги. Пока что ясно одно: бумажная книга как культурное явление не может быть полностью заменена цифровой.