Текстобзор 10: ИнфоРост
27.10.2022
Оглавление
Описание
Платформа ИнфоРост (английская версия dlibrary) — CMS для библиотек и цифровых архивов. Разрабатывается примерно с 2010 года в компании ИнфоРост.
Платформа позволяет задать структуру сайта, управлять его наполнением, настроить его внешний вид. Платформа обладает развитыми средствами управления контентом, имеет современный и простой в использовании пользовательский интерфейс. Среди прочего эта система позволяет вводить любые метаданные, в том числе в библиотечных и архивных стандартах, предоставляет многофункциональный просмотрщик страниц, обеспечивает автоматическое формирование указателей, полнотекстовый поиск по метаданным и страницам, тайловый просмотрщик крупных изображений (например карт), размещение аудио и видео, систему управления ролями пользователей, автоматическое формирование отчетов статистики по использованию дискового пространства, по посещаемости.[1]
Система разработана на Ruby on Rails + PostgreSQL. Решение основано на свободных технологиях, но само является закрытым.
В настоящий момент мы не уверены, когда и по какой модели выпускать код платформы в качестве открытого. Мы даже не уверены, нужен ли вообще российскому информационному сообществу открытый код платформы ИнфоРост. А если нужен, то в каком формате лучше обеспечить разумную долгосрочную инфраструктурную поддержку такому проекту? Ответов на эти вопросы у нас пока нет.[2]
Использовать ИнфоРост можно в двух вариантах: развернуть на своём сервере и приобрести ресурсы и хранилище у компании.[3]
Примеры проектов на системе:
Электронная библиотека Государственная публичная историческая библиотека России
Российско-германский проект по оцифровке германских документов в архивах Российской Федерации
Архивы всемирно известных ученых-дефектологов (включает материалы по Загорскому эксперименту) (Видео-презентация)
Число проектов на платформе ИнфоРост неизвестно, предположительно оно должно быть в диапазоне 10-50 проектов.
Просмотр документов
Технология просмотра страниц — разработка компании и названа Docview.
Просмотрщик страниц (или Docview) ‒ это фирменная разработка ИнфоРост, он позволяет просматривать изображения при разных увеличениях, и обладает несколькими режимами работы. Прикрепленные к узлу изображения станут автоматически доступны на его странице в Docview. Docview легко может работать с тысячами страниц одновременно. Рассмотрим функциональные элементы просмотрщика в режиме постраничного просмотра. В разных режимах доступны разные возможности.[4]
Docview выглядит стандартно для такого рода программ и уступает в удобстве чтения по сравнению с программами для чтения PDF: например, нельзя перетягиванием мыши прокрутить изображение.
По сравнению с Vivaldi скорость работы выше, но в целом оба средства просмотра не очень удобны для чтения онлайн.
Присутствует функция скачивания отдельной страницы и всего файла. Но, вероятно, эти функции могут быть отключены, например, в гос. публичной исторической библиотеке возможность скачивания всей книги отсутствует:
Мы постоянно работаем над развитием электронной библиотеки, но на данный момент целиком скачать издание нельзя.[5]
Особенностью Docview является просмотр крупных изображений, например, карт.
Просмотрщик страниц крупного размера позволяет изучить отдельную страницу более подробно чем это позволяет Docview. Чтобы обеспечить такую возможность используются технологии тайловых карт на подобии тех, что использует Google Maps. Для любой страницы размещенной на Платформе администратор может создать карту щелчком мыши. После этого карта сгенерируется и ссылка на нее станет доступной из Docview. Данная технология позволяет без потери качества и без длительной загрузки обеспечить просмотр изображений разрешением до 32768 пикселей в ширину. Просмотрщик обеспечивает 32-х кратное увеличение и возможность работы в полноэкранном режиме.[4:1]
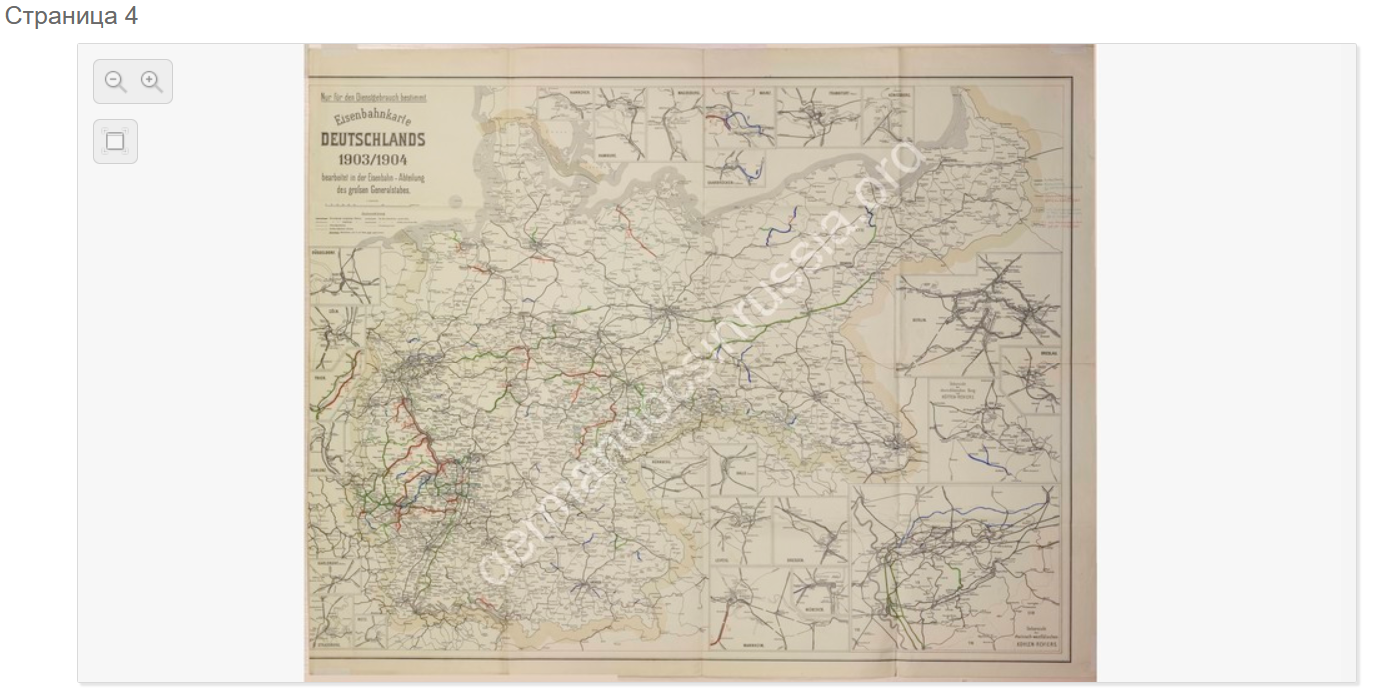
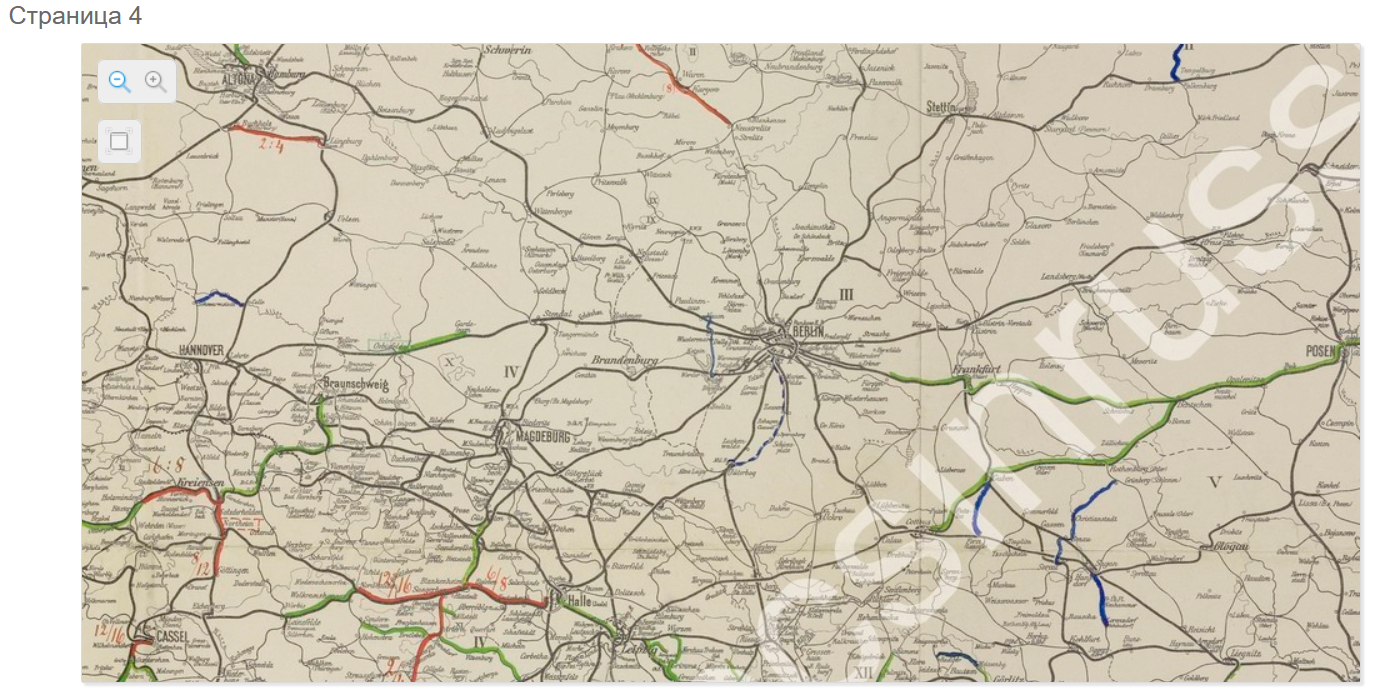
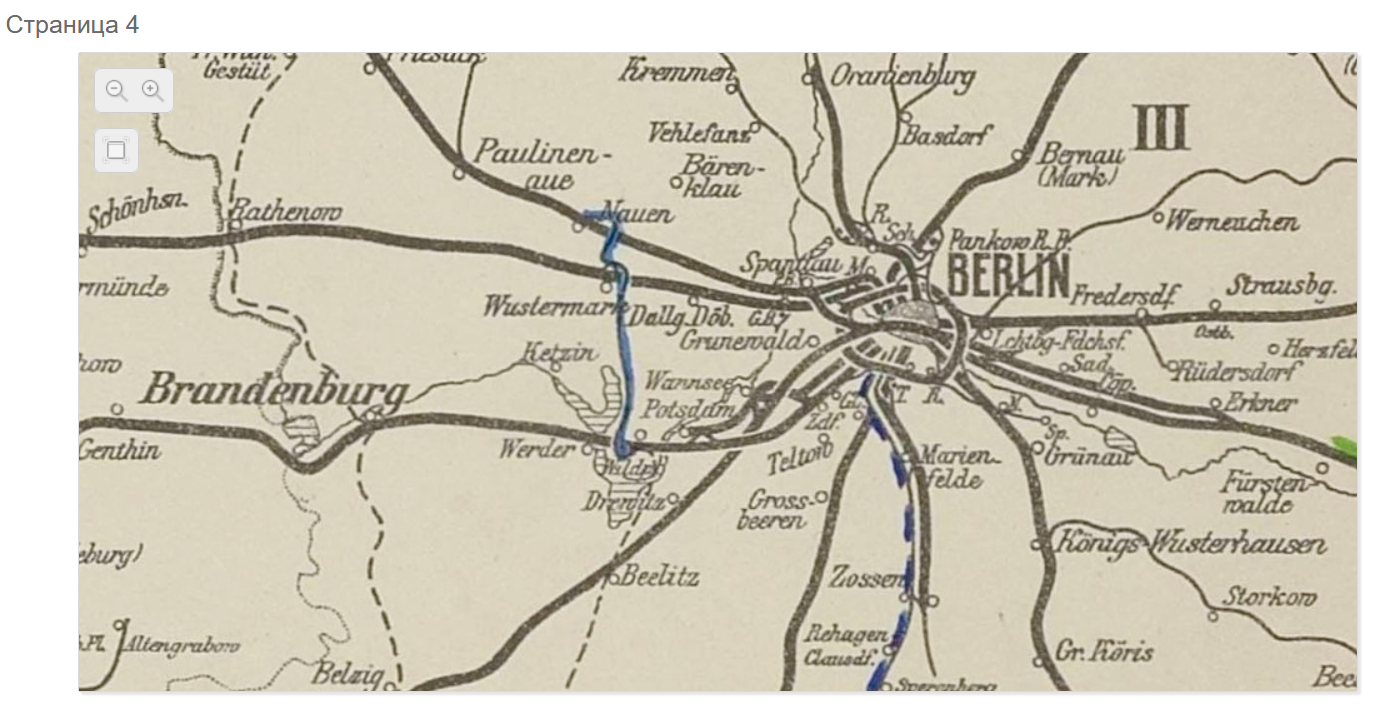
В Docview есть возможность отображения текста рядом с изображением.

Указатели
Каждый материал в системе может содержать метаданные в формате тип-значение. Возможными типами метаданных могут быть издательство, автор, серия и т. п. Набор типов настраивается администратором системы.
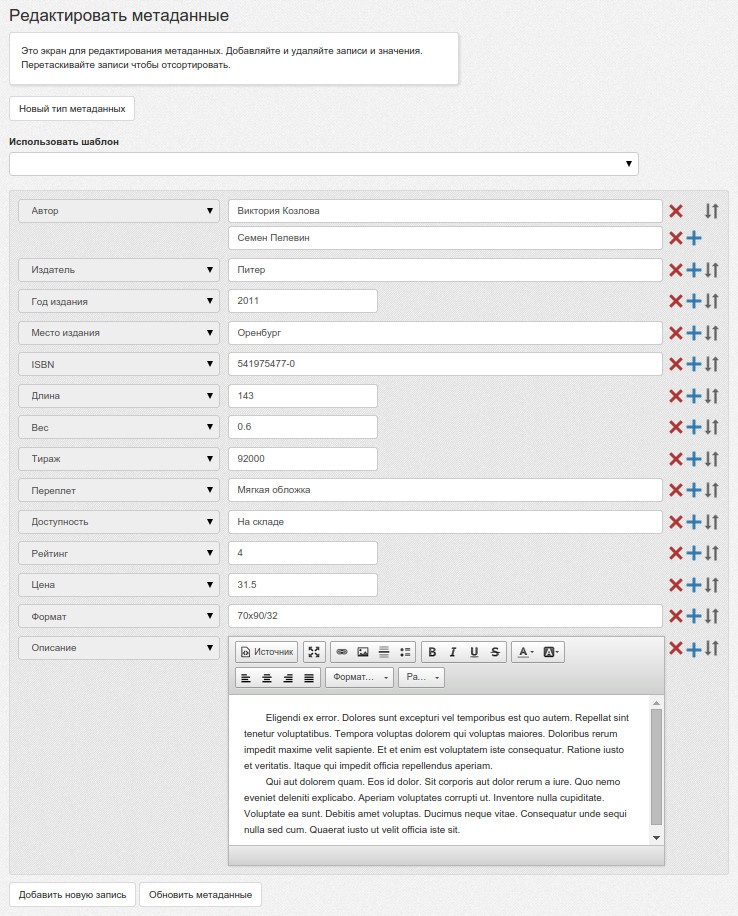
На основе этих данных строится указатель.
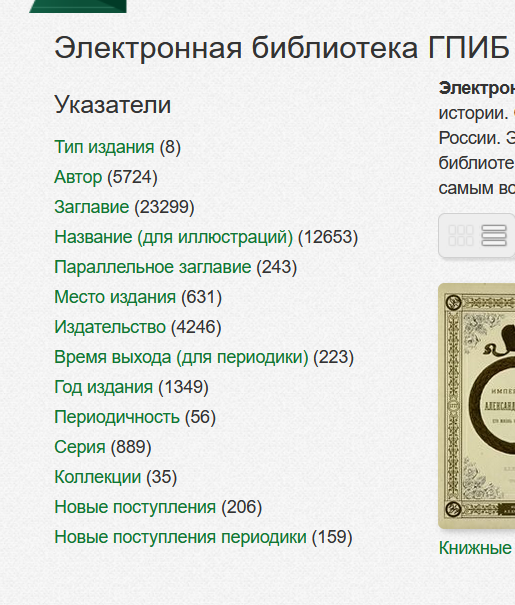
Указатель просто группирует материалы по типу метаданных. При выборе типа у в указателе появится список значений этого типа.
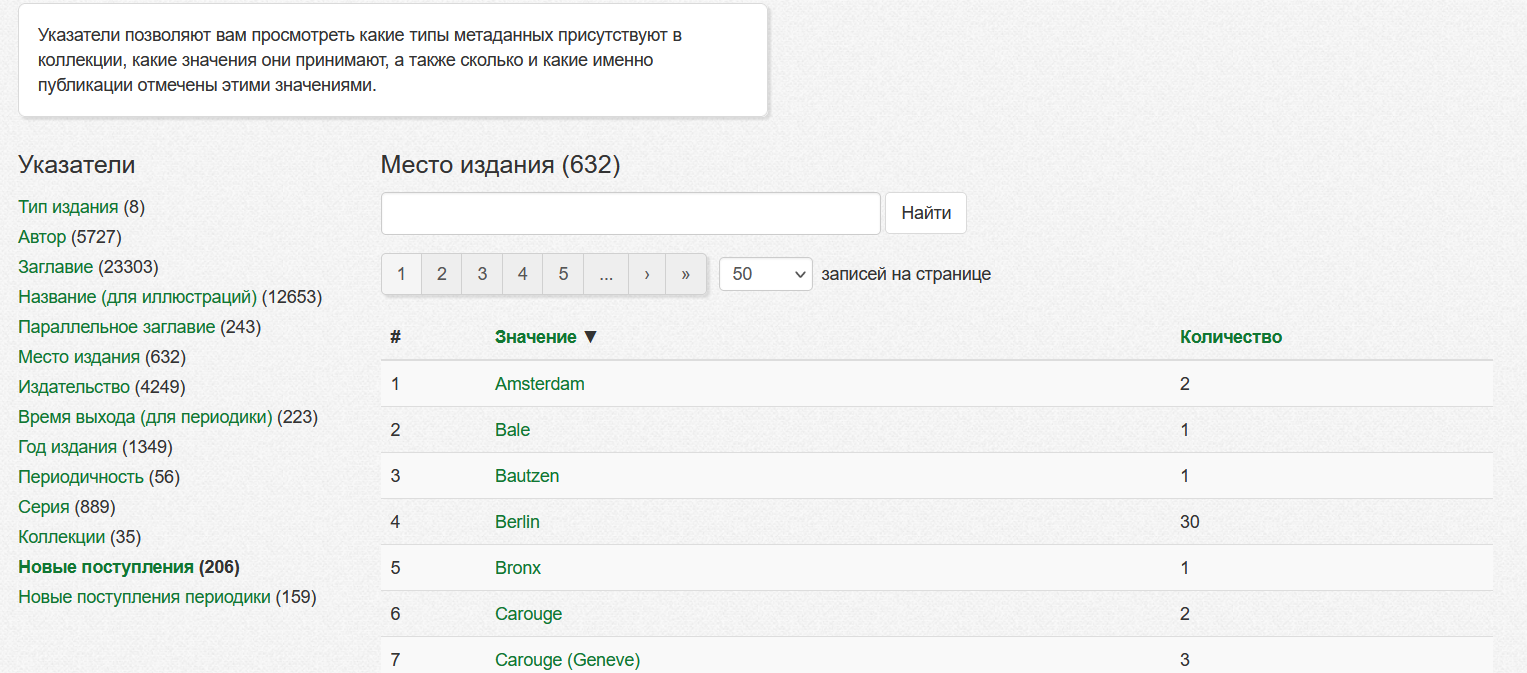
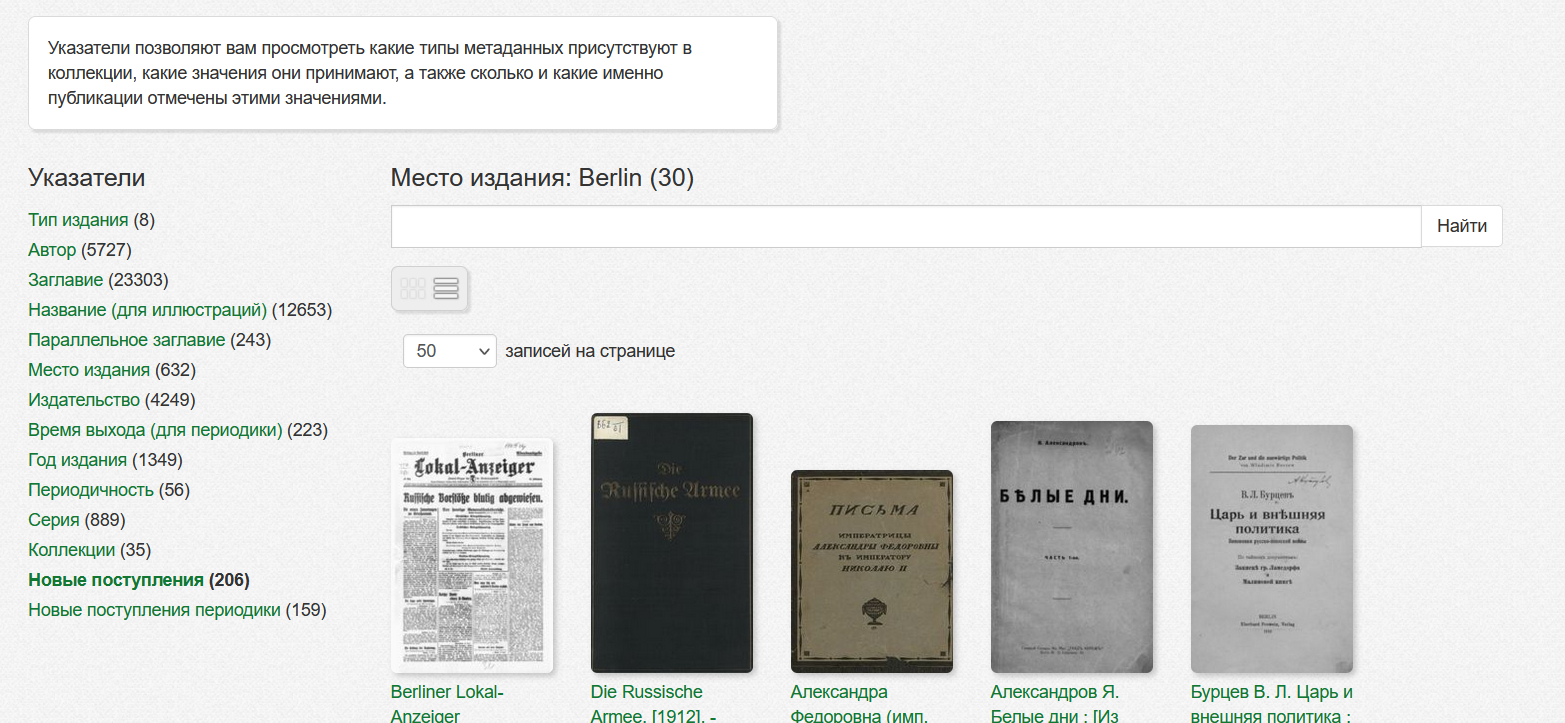
При выборе значения появится список материалов в которых у выбранного типа метаданных установлено указанное значение.
Поиск
В системе есть расширенные возможности поиска включая поиск по метаданным, поиск по содержанию и расширенный язык поисковых запросов.
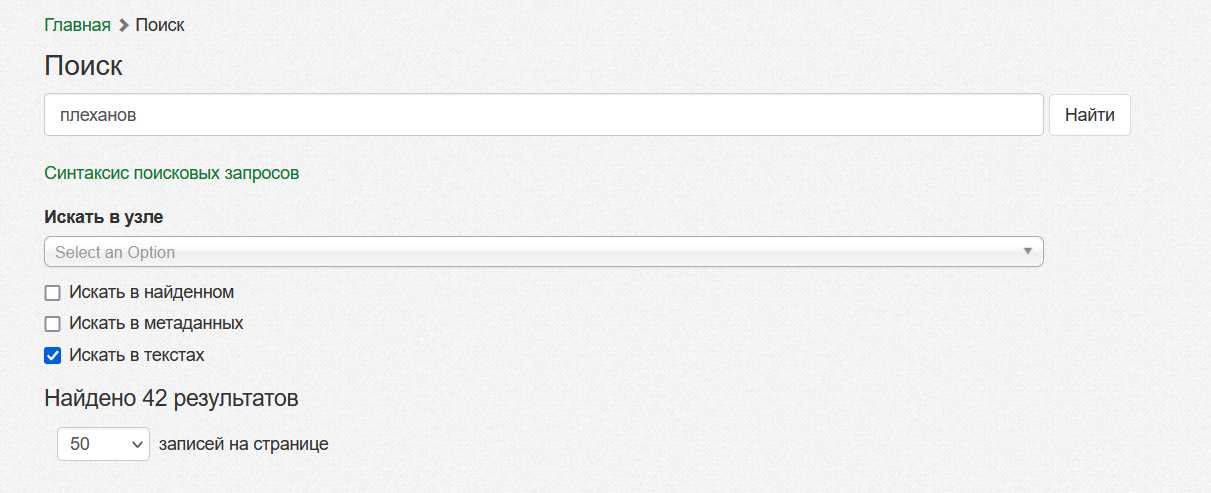
Поиск происходит по тексту в узлах, их метаданным, и текстам их страниц. Движок поиска понимает грамматику многих языков, а также структурированные запросы поисковика Lucene. ... Какие метаданные участвуют в поиске и какие из них отображаются в результатах может настраиваться администратором.[4:2]
Синтаксис поисковых запросов описан на отдельной странице. В качестве поискового движка используется Lucene.
Другие функции платформы
Платформа ИфоРост так же имеет стандартные для CMS функции: контроль доступа, пользовательские роли, редактирование отдельных страниц. Есть отдельные функции для работы с большим количеством документов: массовое изменение метаданных, шаблоны метаданных, разделение коллекций и др. [4:3]
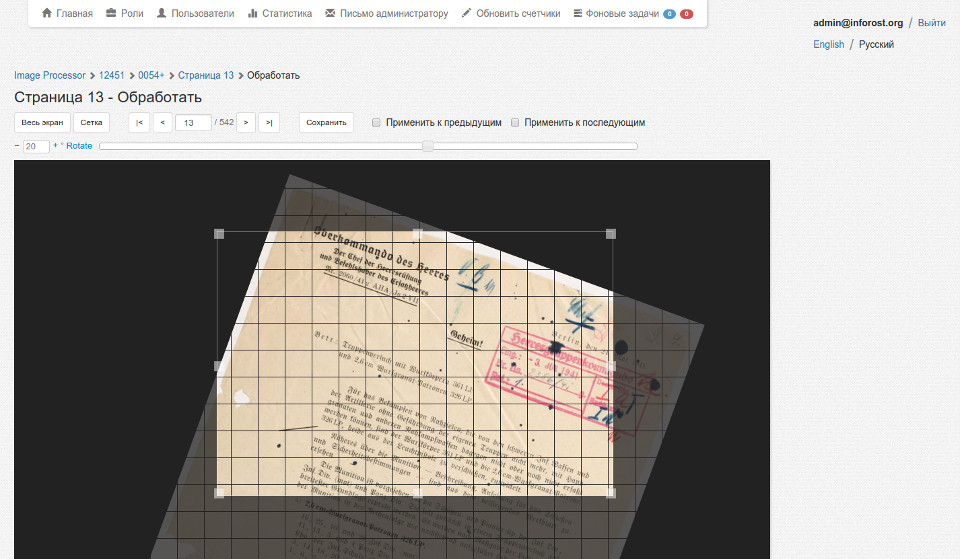
Сканирование
Помимо средств для разработки, Компания ИнфорРост предоставляет оборудование для сканирования и последующей обработки изображений. Обработка заключается в обрезании и выравнивании сканов книг, про средства распознавания текста информации нет.[6]
Исследования
Инфорост интересен не только технологической платформой. Авторы не просто делают продукт, а развивают и исследуют область оцифровки и представления цифровых архивов. В этом плане очень интересен сайт одного из участников проекта Фесенко Кирилла на котором расположено большое количество ссылок на тему цифровых архивов.
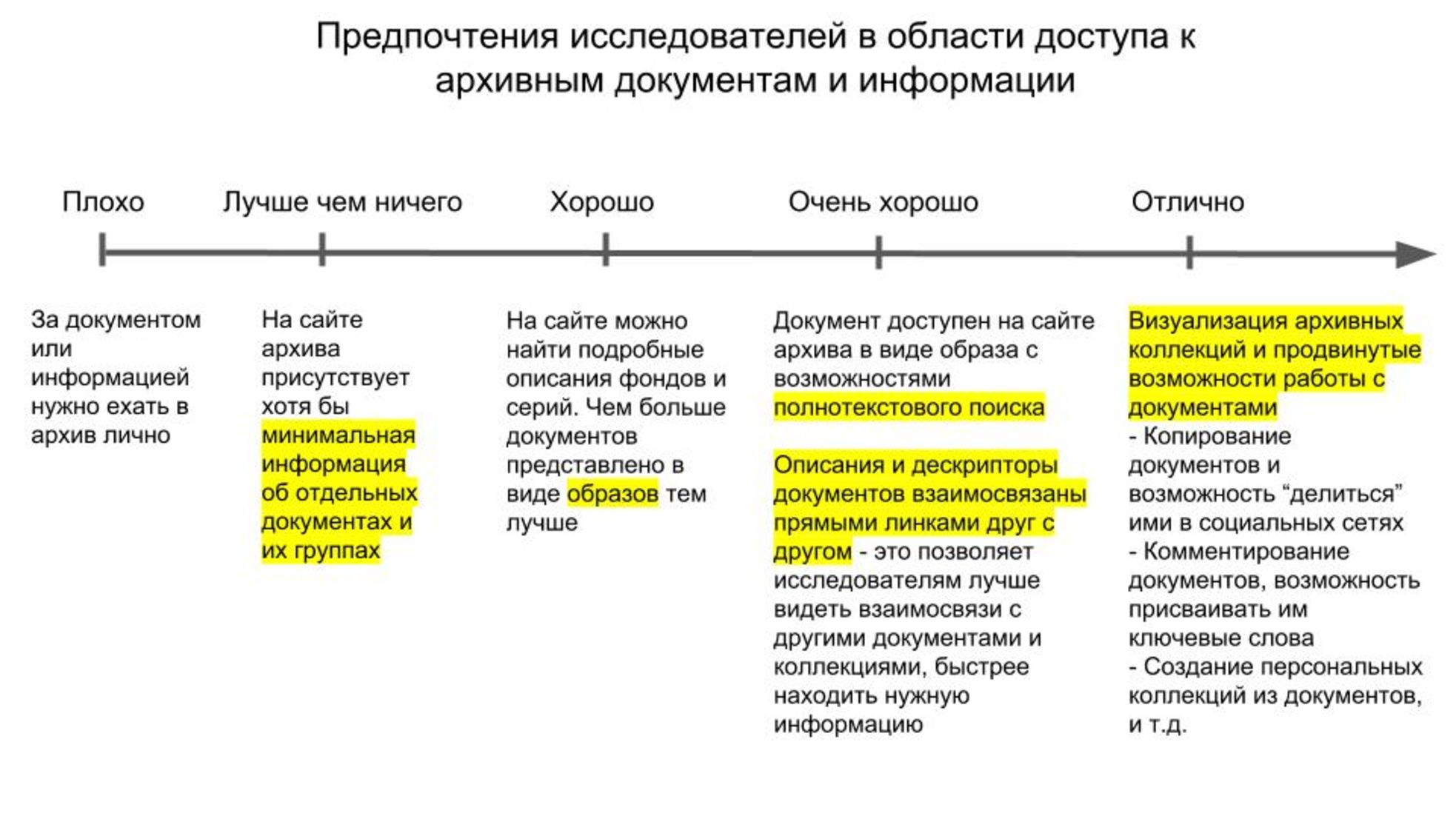
Полезные материалы с сайта Фесенко Кирилла материалы:
Организация оцифровки и размещения изданий в Открытой электронной библиотеке ГПИБ
Подход к описанию малоизученных архивов ученых-дефектологов (проект)
Заключение
ИнфоРост решает определенные задачи — предоставление доступа к цифровым архивам сканированных изображений. Есть модули для полного цикла работы архива: сканирование, обработка, размещение на сайте и отображения. Детали, вроде расширенного поиска, показывают, что платформа разрабатывается с учетом реальных потребностей.
Целей распознавания текста, на данный момент, в проекте нет.
Отдельно стоит отметить обозначенные выше исследования области цифровых архивов, это очень хорошее исключение в рамках подобных проектов.