Текстобзор 5: Библиотека электронных ресурсов исторического факультета МГУ
26.09.2022
Оглавление
Описание
Библиотека электронных ресурсов [1] — это попытка создать электронный каталог исторических источников подходящий для научной работы. Проект развивался с 1999 по 2013 года, основной разработчик Тимур Якубович Валетов.
Электронные тексты
Большинство электронных текстов представляют из себя HTML-страницу, где содержимое книги оформлено внутри тега pre, с помощью которого имитируется деления текста на страницы. Номер страницы находится справа от текста. Пример Византийская Книга эпарха:

Номера страниц не размечены для создания ссылки с помощью якоря. В некоторых случаях для комментариев применяется отдельный фрейм, это позволяет скролить основной текст и комментарии независимо друг от друга.
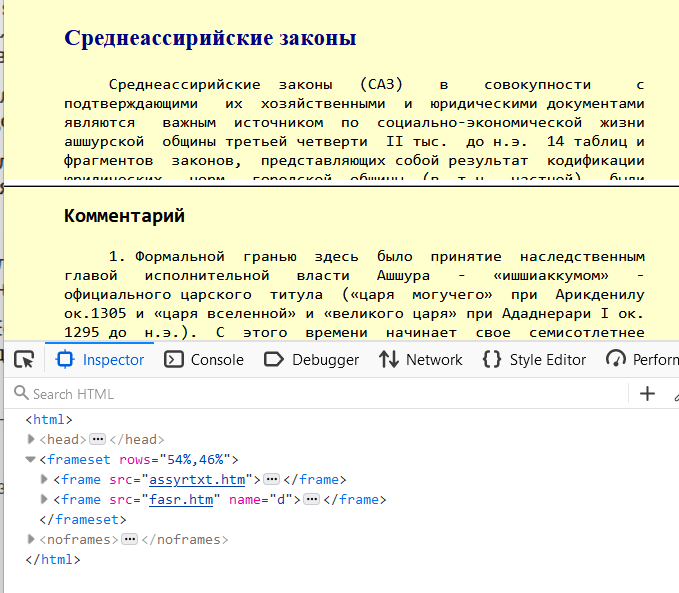
В некоторых книгах есть HTML оглавление.
Часть материала размещается просто в HTML без тега pre, примеры: Cтранствия Cинухета, Эклога. В этом случае примечания сделаны с помощью якорей, а отметки страниц с помощью тега span и номера в фигурных скобках.

На сайте используется кодировка windows-1251. Стоит отметить, что использование каких-либо кодировок для текстологических работ кроме Unicode на данный момент нецелесообразно.
Материалы сгруппированы по историческим периодам, кроме размещенных на сайте материалов есть много ссылок на материалы на другие ресурсы. Каталог, скорее всего, наполнялся вручную с помощью редактирования HTML страниц. Если это действительно так, то такой способ ведения каталога может быть использован только для относительно небольшого числа материалов. На данный момент рационально использовать CMS либо другие способы генерации страниц каталога из базы данных. Без базы данных, даже такое простое действие как добавление списка материалов по определенной теме вместо деления по историческому периоду, потребует больших трудозатрат в виде ручного редактирования HTML страниц.
Фотокопии исходных материалов отсутствуют, за исключением некоторых случаев: диаграмм и фотографий обложки.
Тексты были вычитаны перед размещением:
Насколько можно, мы стараемся снабжать тексты краткой источниковедческой аннотацией и научными комментариями. Одним из предметов особого внимания является стремление к максимальному соответствию нашей электронной версии оригинальному изданию - большое время уходит на тщательную вычитку, проставляется нумерация страниц. Проблема в том, что, с одной стороны, уже давно разработаны правила оформления научных изданий, и их необходимо соблюдать, а иначе научная ценность издания уменьшается. Публикация текстов в ныне существующих в Интернете библиотеках, к сожалению, чаще всего совершается для любительского ознакомления и не претендует на научную строгость. Нельзя допускать использование таких правил в серьезных электронных библиотеках. С другой стороны, существуют просто технические сложности с переводом некоторых деталей системы оформления традиционных научных изданий в Интернет. Один из примеров этого — невозможность автоматического переноса в электронное издание традиционной системы разметки страниц (или, в более обобщенном виде, системы возможности ссылок на источник). Если электронное издание напрямую копирует книжное издание, то еще можно по-разному решать, как расставлять в файл номера страниц копируемой книги, но если на сайт выставляется материал неопубликованный или вообще не очень вписывающийся в традиционную систему (например, база данных), то это становится проблемой.[2]
Базы данных
Раздел Базы данных содержит базы данных, связанные с историческими исследованиями. Базы данных находятся в форматах Microsoft Access и Microsoft Excel, описания к ним находятся или сразу на сайте или в документе Microsoft Word.
Большинство баз данных состоит из основной таблицы и нескольких справочников. Базы данных не связаны друг с другом. В некоторых базах данных (пример) в одной из колонок в текстовом поле добавлен источник записи.
Основные недостатки раздела это отсутствие единого подхода к описанию баз данных и использование коммерческих продуктов (Access, Word, Excel). Проблемы которые авторы пытались решить этим разделом сайта были обозначены на круглом столе Д. А. Гутновым [3]:
Другой стороной этой же проблемы является "вторичное" использование баз и банков данных. Созданные в свое время для решения определенных научных целей, эти базы часто выставляются на различных сайтах в Интернете для вторичного использования. При этом предполагается, что вторичное использование подразумевает повторную обработку содержащихся в этих банках данных сведений, но по другим методикам. Между тем, спектр использования такой информации гораздо шире. Опубликованные таким образом данные могут быть востребованы и как цитата и как иллюстрация и как ссылка и т. п. В связи с этим недостаточным представляется упоминание в описании банка данных лишь названия архива или номера описи, откуда извлечены опубликованные в электронном формате сведения. Строго говоря, нужно стремиться к тому, чтобы каждый содержащийся в банке данных факт был идентифицирован с источником. Возможно, на нынешнем этапе в силу указанных выше обстоятельств развития процесса информатизации этот идеал и недостижим. Именно безупречно разработанный научный аппарат отличает научные электронные продукты от их коммерческих аналогов, о которых речь пойдет ниже.
Хорошо дополняет проблему комментарий Ю. Ю. Юмашевой
По второй теме мне представляется, что следует учитывать следующее: существуют как минимум два подхода в разработке баз данных — источниково- и проблемно- ориентированный. Если к вторичной публикации базы данных, созданной в рамках первого подхода, можно предъявить требования, заявленные Д.А. Гутновым, то с проблемно-ориентированными базами данных дело обстоит сложнее. Идеальный вариант работы с такой базой данных, который предлагает Д.А. Гутнов, нереален, поскольку не учитывает тот факт, что данные того "интегрированного искусственного метаисточника", который в просторечии именуется "базой данных", могли быть собраны из многих тысяч обработанных "первичных" источников. Более того, эти источники могли проходить этап, условно называемый "выбраковкой", когда из массы разноречивых сведений методом перекрестного анализа выбиралось наиболее достоверное. При этом фиксация того, откуда брались эти сведения, совершенно необходима! Но сведения могли совпадать в 15-ти источниках, а в 16-ом отличаться. Какие источники указывать? А если данные, заносимые в запись базы, вообще интегрированы из фрагментов разных источников? Что делать в этом случае? Объем такой работы, равно как и создаваемые в ходе ее осуществления "опросно-перекрестные" таблицы, превышают объем "результирующей" базы данных в сотни, а иногда в тысячи раз! Эти слова подтверждаются опытом моей работы над базой данных "Командармы", где первоначально "в работе" участвовали более 2500 открыто опубликованных источников, сведения которых "просеивались" через подобные таблицы. Могу с достоверностью утверждать, что публикация этих таблиц в силу их объема просто физически невозможна.
Есть лишь один выход: одновременная публикация "результирующей" фактологической базы данных и вспомогательной, взаимосвязанной с первой, базы данных, созданной на основе всей привлеченной к исследованию литературы и источников с указанием их выходных данных или данных архивного хранения. Лишь такой подход реален на современном этапе.
Другое
В разделе с оцифрованными источниками, источники представлены в виде HTML станицы со ссылками на изображения, изображения в формате jpg с высоким разрешением.
Если рассмотреть пример библиографии одного из проектов, то она так же представляет из себя просто HTML страницу со списком литературы.
На сайте есть ещё разделы: литература в PDF, ссылки, материалы полезные только для МГУ и др.
Заключение
Проект «Библиотека электронных ресурсов исторического факультета МГУ» содержит в себе хорошие идеи: вычитка электронной версии, сохранение нумерации страниц, добавление ссылок на источники в базы данных и другие. Основная проблема проекта — низкий технический уровень реализации который можно связать с годами когда проект развивался (1999-2013), а так же с тем что для авторов область информационных технологий не профильная.
Описание проекта частично взято из стенограммы круглого стола «Историк, источник и Интернет» опубликованной в журнале Новая и Новейшая история, 2001, №1 (скачать можно с rutracker), страницы 76-81. ↩︎
Журнал «Новая и Новейшая история» 2001, №2, стр. 80. ↩︎
см. примечание 1. ↩︎