Текстобзор 17: параллельные переводы «Слова о полку Игореве» и «Поэтики» Аристотеля
15.10.2025
Оглавление
Описание
«Слово о полку Игореве» и «Поэтика» — корпусы параллельных переводов. Они размещены на сайте Бориса Орехова вместе с другими филологическими проектами.
Параллельные переводы сложно визуализировать. Бумажная книга накладывает серьёзные ограничения:
Дело в том, что формат книги даёт для решения этой задачи очень ограниченные возможности. В общем, параллельное представление текста и перевода — вполне привычная эдиционная практика, не раз реализованная и в публикациях «Слова…». Но как расположить переводы в книге? Читателю удобнее всего иметь нужные тексты перед глазами, но определить, какие именно тексты и в каком порядке понадобятся, а какие окажутся лишними, заранее невозможно; статический же характер бумажного издания предопределяет, что этот выбор должен быть сформирован раз и навсегда. Неудобства для пользователя здесь очевидны. Вторая проблема в этом ряду — расположение текстов. Книжный формат даёт возможность предложить читателю для одновременного ознакомления два, максимум — четыре текста, которые размещаются слева и справа на развороте или втиснуты в две-три колонки (большего не позволит ширина страницы) на одном листе. (О проекте)
Электронные издания имеют больше возможностей, но приходится учитывать следующие особенности параллельных переводов:
- Переводов много, и все сразу увидеть невозможно; для каждой задачи требуется свой набор.
- Визуализация параллельных текстов имеет недостатки. Существует два основных варианта: вертикальное расположение текстов в столбцах и горизонтальное — друг под другом.
- Поскольку тексты объёмные, их неудобно отображать целиком, особенно при горизонтальном расположении. Поэтому тексты следует разделять на части. В качестве частей обычно выступают абзацы.
- Полезно выделять параллельные предложения на разных языках, но это не всегда возможно: переводы не всегда совпадают ни по структуре предложений, ни по делению на абзацы.
«Слово о полку Игореве»: Параллельный корпус переводов
Корпус разрабатывается с 2007 года.
Новый этап в развитии проекта начался в мае 2008 года, когда стало известно о том, что Российский гуманитарный научный фонд поддержал развитие корпуса грантом № 08–04–12104в. За отчётный период в корпус добавлено 176 текстов на 40 языках.
В оцифровке текстов приняли участие более 25 человек.
Используемые технологии. На фронтенде применяется Bootstrap для оформления интерфейса. Бэкенд написан на Python, вероятно, без использования фреймворков. Для хранения текстов, скорее всего, используется база данных.
Работает корпус следующим образом. На главной странице читатель выбирает до шести переводов.
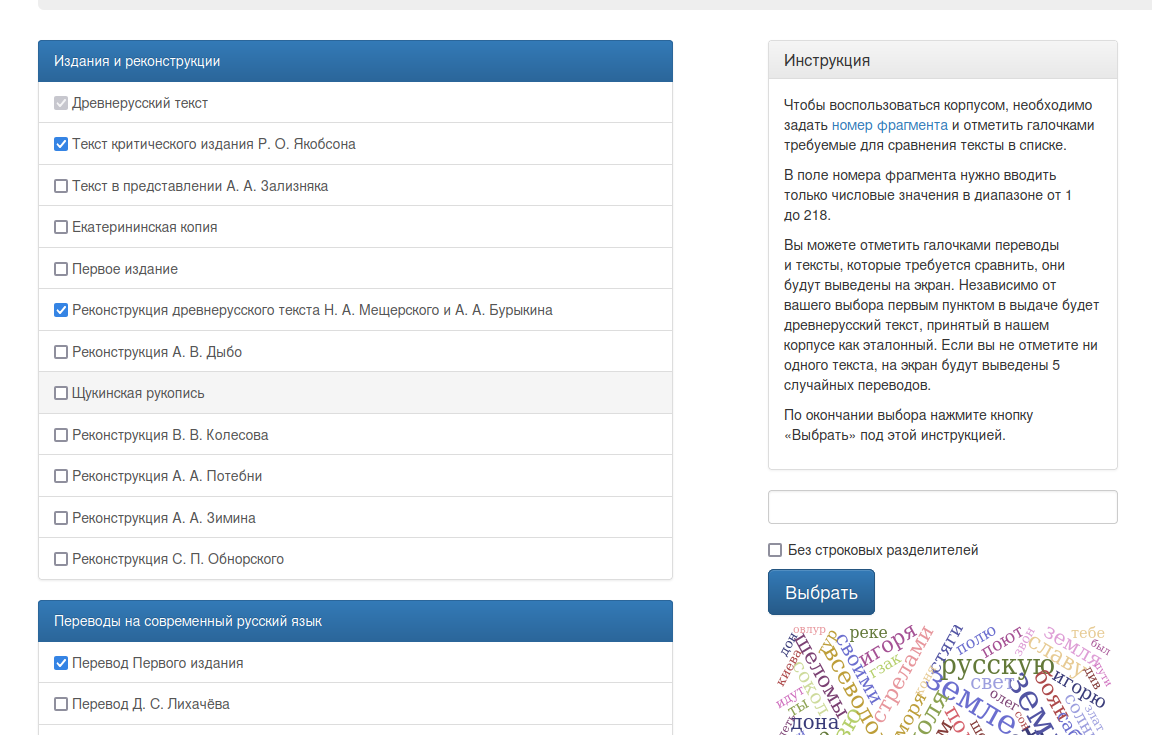
Затем начинается чтение по фрагментам. Фрагменты выделены на основе определённого издания оригинального текста. Выбранные переводы располагаются сверху вниз.
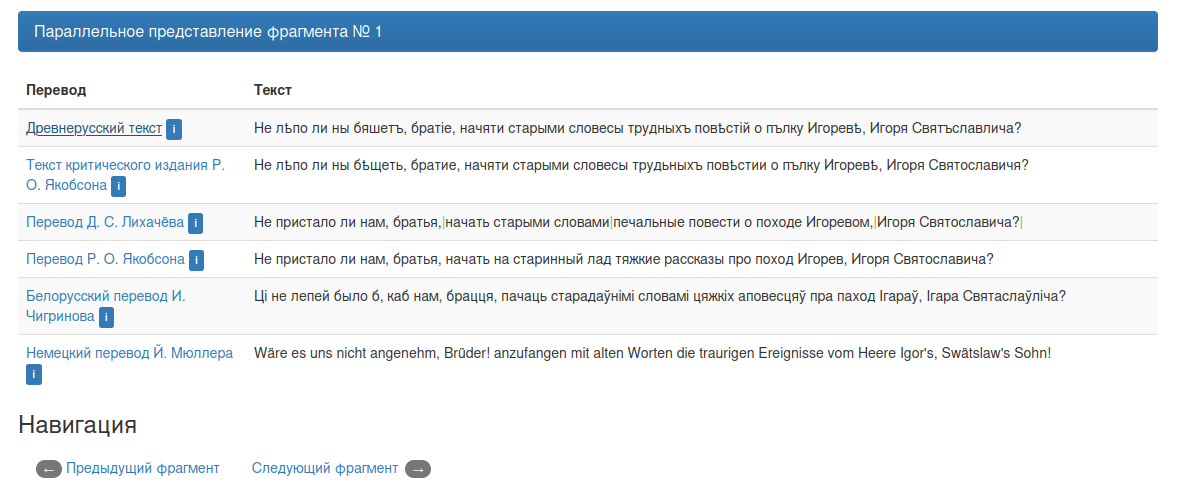
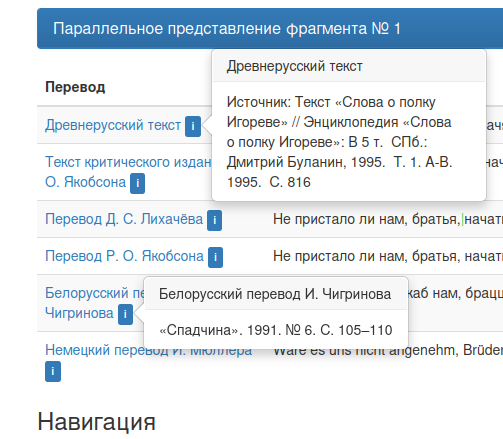
Для каждого выбранного перевода по клику открывается описание издания. Описание остаётся открытым до повторного клика на метку
Все параметры отображения передаются в URL, поэтому легко поделиться ссылкой на точный набор переводов для определённого фрагмента.
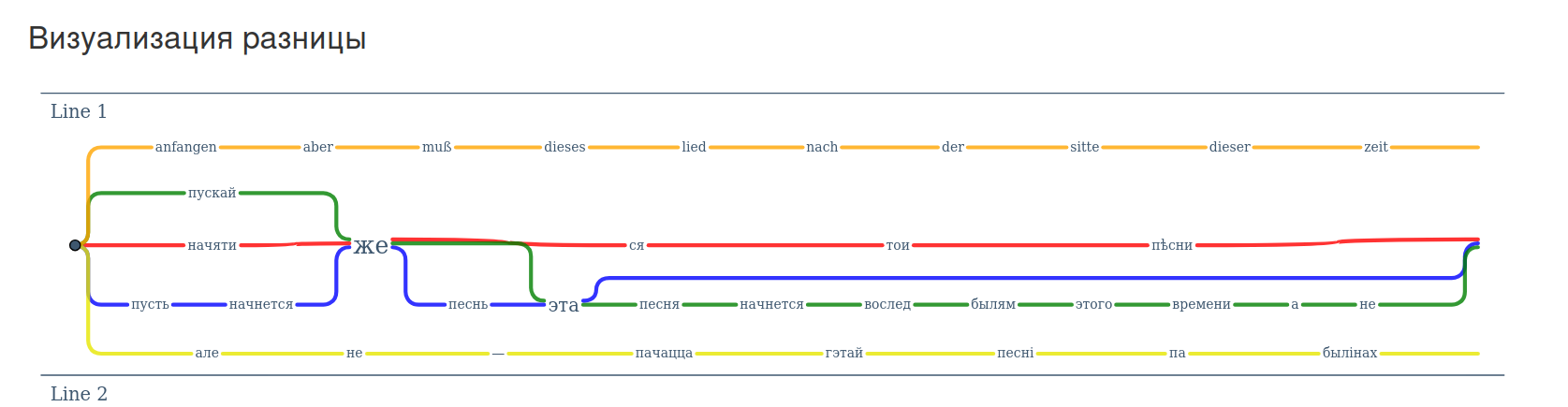
Внизу страницы расположен график сравнения текстов, построенный с помощью traviz.vizcovery.org. Этот инструмент требует отдельного рассмотрения.
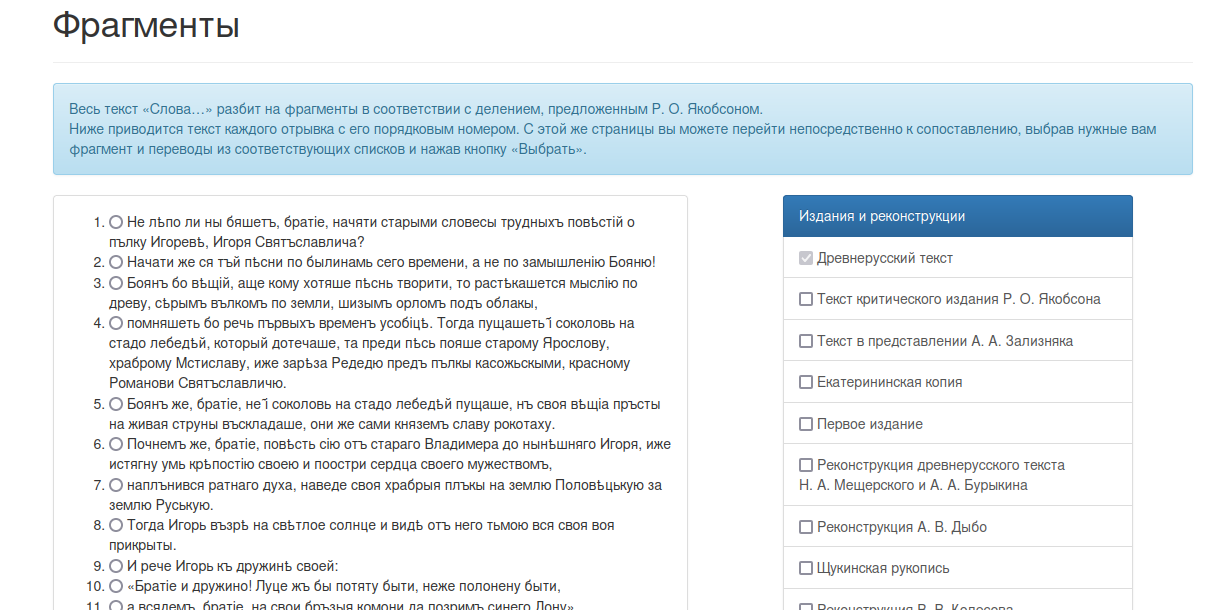
Полный список всех фрагментов находится на отдельной странице. Там читатель выбирает фрагмент и нужные переводы, после чего чтение начинается с выбранного места.
В некоторых переводах строки разделяются символом |. Кнопки для отключения этого режима найти не удалось.
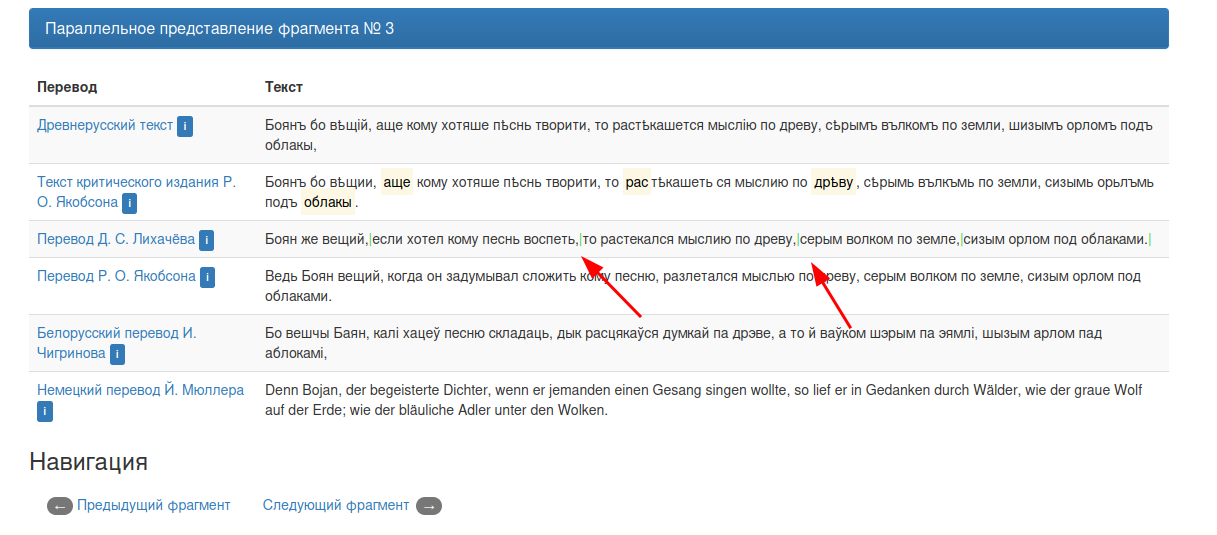
«Вытянутые» в строку поэтические переводы также лишаются своего традиционного облика колонки, но такое фундаментальное свойство стихотворной речи, как деление на строки, в корпусе сохраняется, отмеченное специальным знаком, вертикальной чертой: "|". Строфы отграничиваются друг от друга двумя вертикальными чертами: «||». Деление на абзацы в прозаических переводах не оговаривается. Деление на логические части, предпринятое рядом переводчиков, также не учитывается, их названия опущены. Не воспроизводится пагинация Первого издания и Екатерининской копии: пользователь может обратиться к любому дипломатическому их воспроизведению. Пользователю также дана возможность по его желанию просматривать текст без символа "|", если граница стиха для него не важна, а вертикальная черта мешает восприятию. (О проекте)
На сайте есть форма для сообщения об ошибках.
Реализован поиск с учётом морфологии и дополнительными условиями.
Как именно работают дополнительные фильтры — неизвестно.
Аристотель «Поэтика»
«Поэтика» реализована проще, чем «Слово». На главной странице находится список фрагментов.

Для каждого фрагмента открывается заранее заданный набор переводов.

На сайте доступны следующие переводы:
- Перевод М. Гаспарова
- Перевод В. Аппельрота
- Перевод Н. Новосадского
- Translated by W. H. Fyfe
- Translated by S. H. Butcher
- Translated by I. Bywater
- Traduction Ch. Emile Ruelle
- Перевод Абу-Бисра, не позднее 940 г.
Заключение
Параллельные переводы важны и нужны. В описании проекта приведена удачная цитата на эту тему:
«Каждый перевод, сколь бы он ни был превосходен, проецирует многомерную сложность подлинника на плоскость, делает оригинал упрощённым и представляет его односторонне. Сопоставляя два или несколько переводов, читатель может получить как бы стереоскопическое изображение оригинала, увидеть его с разных сторон».
-- М. Л. Гаспаров. О новом переводе «Ада» Данте, выполненном В. Г. Маранцманом // Данте Алигьери. Божественная комедия: Ад. Чистилище. Рай. СПб., 2006. С. 5.
Средства как для создания, так и для отображения параллельных текстов сегодня развиты слабо. Опыт корпусов «Поэетики» и «Слова о полку Игореве» полезен для разработки подобных инструментов. Перспективным направлением развития представляется добавление контекстных словарей для каждого перевода.
Недостаток проекта — закрытость исходных данных. Открытые данные позволили бы создавать собственные инструменты визуализации и анализа. Если же данные остаются закрытыми, вся проделанная работа может быть утеряна вместе с закрытием проекта.