Текстобзор 24: ruarxive.org
01.03.2026
Оглавление
Описание
ruarxive.org — «Национальный цифровой архив России» — организация, занимающаяся архивированием цифровых материалов: сайтов, документов, видео и других.
На сайте опубликованы описание завершенных проектов, база знаний и блог.
Цель инициативы «Цифровой архив» — поиск и сохранение веб-сайтов и иных цифровых материалов, имеющих высокую общественную ценность и находящихся под угрозой уничтожения.
Основная задача проекта — заархивировать, что очень скоро может быть уничтожено, удалено, отключено, заблокировано.
Наибольшие риски быть отключенными имеют ресурсы, организации которых имеют риск ликвидации. Например, к этой категории попадают материалы Международного Мемориала или Эха Москвы. (Источник)
Реализованные проекты
На странице статистики указано:
Статистика и показатели работы проекта по сохранению цифрового наследия России.
Общие показатели Масштаб работы
- 500+ проектов заархивировано
- 50+ ТБ архивов накоплено
- 15+ инструментов с открытым кодом
Однако найти сохраненные материалы сложно. На странице Планы архивации написано:
Национальный цифровой архив состоит из множества проектов, связанных общей идеей архивации современного цифрового наследия, включая инициативы по архивации (консервации) онлайн-сайтов по разным тематическим направлениям: религия, история, экономика, наука и многое другое.
Но следующая ссылка на план 2021 года на Google Drive не открывается без доступа.
Сохраненные проекты отображаются на странице. Однако ссылки в колонке storage url выдают ошибку 404 Not Found.
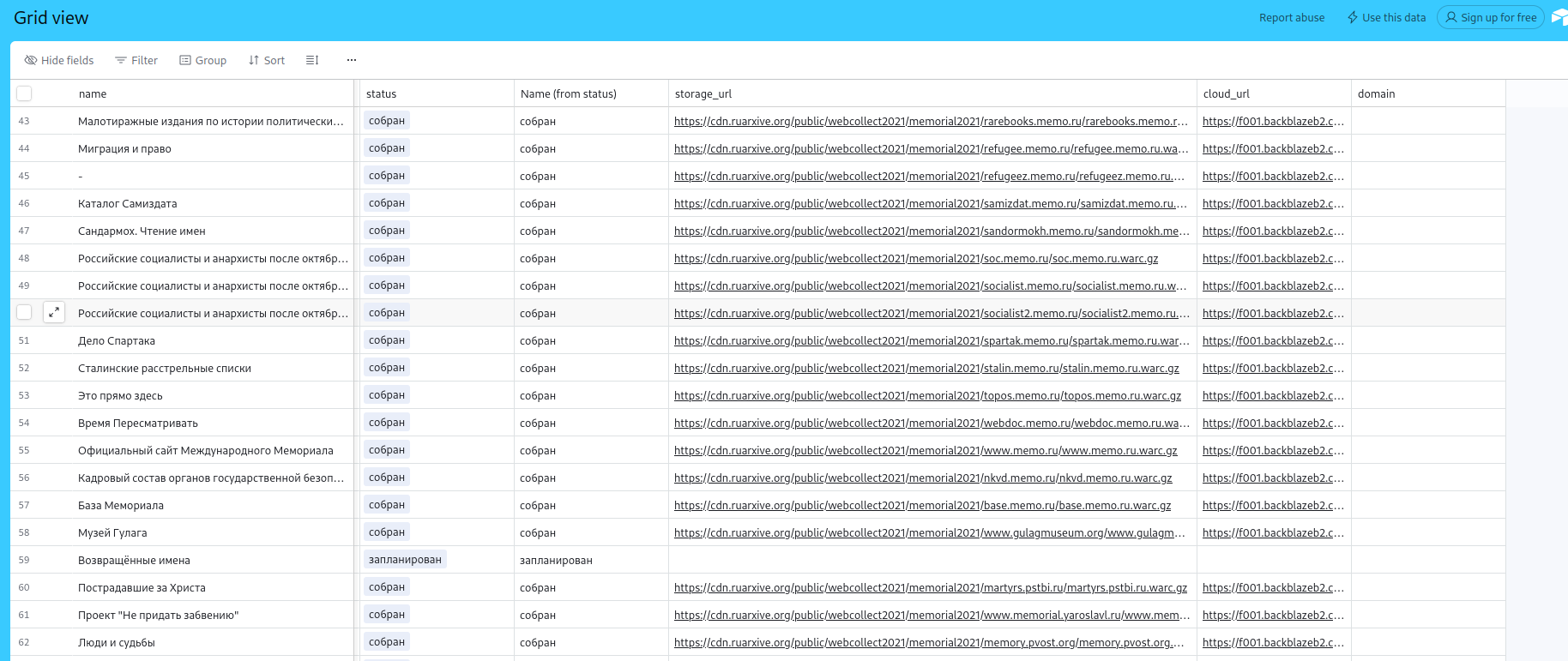
Некоторые ссылки из колонки cloud url работают: скачивают zip-архив, в котором находится файл в формате warc. Открыть warc-файл можно с помощью ReplayWebpage (GitHub).
Также в списке на сайте hubofdata.ru много сайтов, вероятно, архивированных автоматически, но все ссылки на архивы выдают 404. Например, на странице Архив сайта www.sakhalinprokur.ru на 2017-04-03 в формате WARC.
Получается, что проект по созданию цифровых архивов не способен обеспечить сохранность собственных данных.
Социальные сети
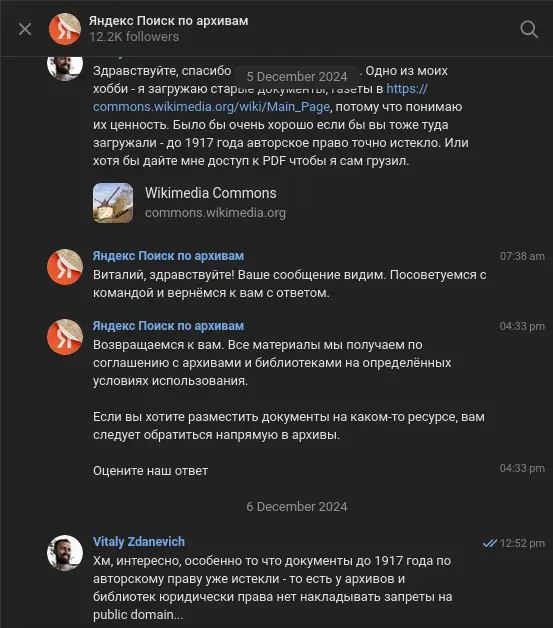
У проекта есть телеграм-канал и телеграм-чат. В канале публикуются новости проекта, обновления сайта и материалы, связанные с темой цифровых архивов. В чате обсуждают эти же темы. Например, есть сообщение о том, что Яндекс не предоставляет исходники используемых материалов:
В канале попадаются полезные ссылки, например: awesome-web-archiving.
Нейросетевой контент
Многие страницы базы знаний и блога выглядят как сгенерированные нейросетью — структурированные, но не написанные для людей. Какую-то информацию извлечь можно, но в основном это названия инструментов и ссылки на содержательные ресурсы.
Запись блога «Архивация цифровых материалов: вызовы и решения»:

Запись блога «Почему исчезают сайты госорганов»:

Запись блога «Архивация комплексных ресурсов: использование нескольких инструментов»:

Тексты сайта зафиксированы в репозитории. Их можно проанализировать нейросетью на вопрос, сгенерированы ли они искусственным интеллектом. Выводы оттуда:
... с очень высокой вероятностью сгенерированы нейросетью. Паттерн типичный: взяты несколько реальных фактов из живых текстов (цитаты, конкретные цифры), а вокруг них сгенерирована раздутая структура с повторяющимися шаблонными разделами.
Судя по фиксациям в репозитории, содержательных работ над сайтом после 2022 года не было. После этого только технические доработки в декабре 2025-го.
Среди материалов сайта интерес представляет «Курс по цифровой архивации» как введение в проблематику.
Заключение
Если текстология концентрируется на отдельных произведениях: книгах, статьях, заметках, — то архивация цифровых материалов направлена на сохранение сайтов целиком. Полный сайт содержит больше информации, чем отдельные статьи: внешний вид, общие страницы вроде главной или страницы об авторах. Да и цифровые архивы сайтов могут не содержать книг или статей, а быть, например, сайтами государственных органов.
Цифровой архив сайта может быть полезен для исторических исследований. Но для распространения литературы и идей он выглядит менее полезным, чем текстология.
Проект ruarxive.org имеет громкое название «Национальный цифровой архив России», но на деле выглядит странно. Как будто сделан просто чтобы был, чтобы можно было отчитаться. Набор сайтов, которые как бы архивированы, но архивы не открываются, содержит много ресурсов, выражающих определенную политическую позицию. Возможно, указанные проблемы можно списать на недостаток людей, что всегда является проблемой в таких проектах.