Текстобзор 2: Весь Толстой в один клик
26.09.2021
Оглавление
Описание
В результате проекта «Весь Толстой в один клик» было оцифровано собрания сочинений Льва Николаевича Толстого. Организацией работ занималась компания ABBYY, так же в участниках упоминаются Государственный музей Л. Н. Толстого и Музей-усадьба «Ясная Поляна». Проект широко освещался в прессе, а к вычитке привлекались волонтеры. Основные работы проводились с июнь 2013 по декабрь 2014.
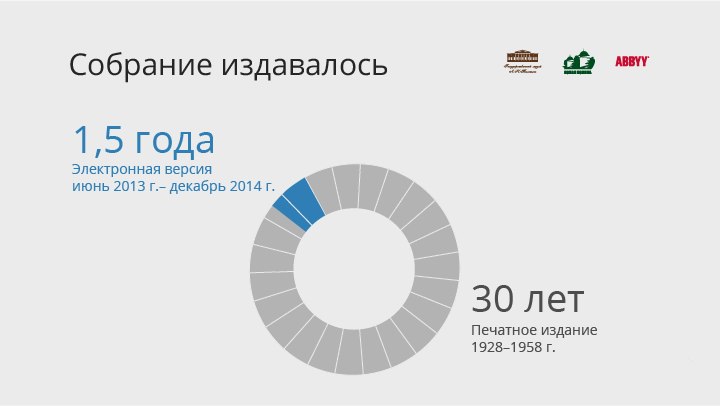
Собрание сочинений включало 90 томов (около 46000 страниц) и издавалось Государственным издательством художественной литературы в 1928—1958 годах.

Цель проекта — получение электронной версии собрания сочинений, по сути набора электронных книг в разных форматах[1].
Результаты проекта размещены на сайте tolstoy.ru. Книги, в основном, представлены в форматах Word, EPUB, FB2 и MOBI. Некоторые книги дополнительно размещены в формате Word. Есть ссылки на онлайн просмотр (HTML), но работают не все (код ошибки 403). На сайте можно скачать как тома целиком, так и отдельные произведения, подборки писем и дневников.
Кроме самих книг, побочными продуктами стали несколько проектов: конкурс плакатов, онлайн марафон «Каренина. Живое издание», цитатник и др. Большинство из них ничем не примечательны, о некоторых будет написано далее.
В разных этапах оцифровки участвовало более 3000 человек:



Самые активные участники были награждены подарками.
Награждала и поздравляла волонтеров директор музея-усадьбы «Ясная Поляна» Екатерина Александровна Толстая. Лучшие участники получили в подарок книгу "Свет Ясной Поляны" И.В. Толстого, электронный ридер Onyx, программу ABBYY Finereader, сертификаты на покупку книг от ЛитРес. [2]
Сканирование
Найти сканы в открытом доступе на страницах проекта не удалось. Судя по всему, сканы появились гораздо раньше проекта
В 2006 году музей-усадьба «Ясная Поляна» в сотрудничестве с Российской государственной библиотекой и при поддержке фонда Э. Меллона и координации Британского совета осуществили сканирование всех 90 томов издания. [3]
В качестве исходных данных, для сотрудников ABBYY сканы пришли в формате PDF:
Собрание сочинений было отсканировано Российской государственной библиотекой в 2006 году, и нам для работы достались PDF-файлы (только изображения, без текстового слоя), один том (а это от 400 до 600 страниц) – один файл. Файлы вместе занимали всего-то навсего 4 Гб. [4]
Сначала сканы поделили на части, по 20 страниц названных «пакетами». С каждого тома получилось примерно по 20 пакетов, следовательно примерно 1800 пакетов на все тома. Затем пакеты были первично распознаны через FineReader, в основном корректировка касалась правильно выделения и расстановки типа (изображение, текст, колонтитул и др.) блокам на скане. Распознанные пакеты загрузили на специально созданную платформу для совместной работы на сайте readingtolstoy.ru. Информация о платформе:
Платформу писали на Ruby в связке с СУБД MySQL, в качестве репозитория и управления разработкой использовалась система BitBucket. Составляющие платформы:
- информационная часть (состоит из статических страниц о проекте, новости, FAQ и т.д.)
- приложение (управляет пользователями, книгами, пакетами и процессами)
- хранилище файлов в исходном, а также во всех промежуточных состояниях фрагментов книг.
Для надежного функционирования всего проекта в целом была использована архитектура на базе облачного хранилища Amazon с возможностью масштабирования. [5]
Скриншот интерфейса платформы:
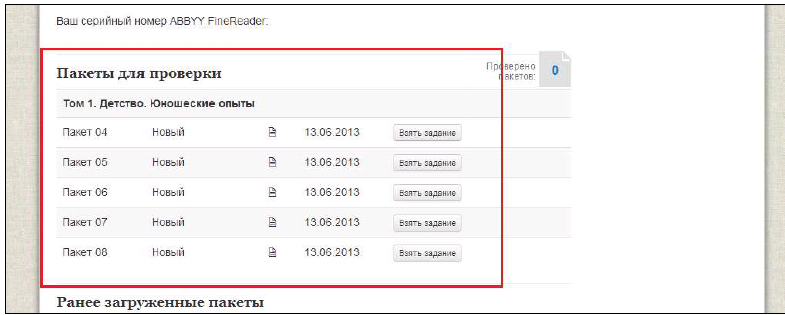
После загрузки файлов начался этап вычитки с привлечением волонтёров.
Вычитка
Вычитка проходила в четыре этапа:
- первичная вычитка;
- аудит вычитки;
- корректировка целого произведения;
- профессиональная корректировка.
Для координации использовался закрытый раздел сайта readingtolstoy.ru и паблик vk.com/readingtolstoy. На сайте можно было скачивать файлы для вычитки и загружать результаты, а так же там размещались инструкции. В паблике были оповещения о ходе работ и ответы на вопросы от участников.
На первом этапе они должны были проверить все тексты, чтобы исключить возможные ошибки, возникшие при оцифровке. Любой человек мог зарегистрироваться на сайте проекта, скачать специальную версию ABBYY FineReader и пакет из 20 страниц текста Л.Н. Толстого, которые он должен был в течение 48 часов проверить и загрузить обратно. [6]
Вычитка проходила в FineReader. Скриншоты от участников:
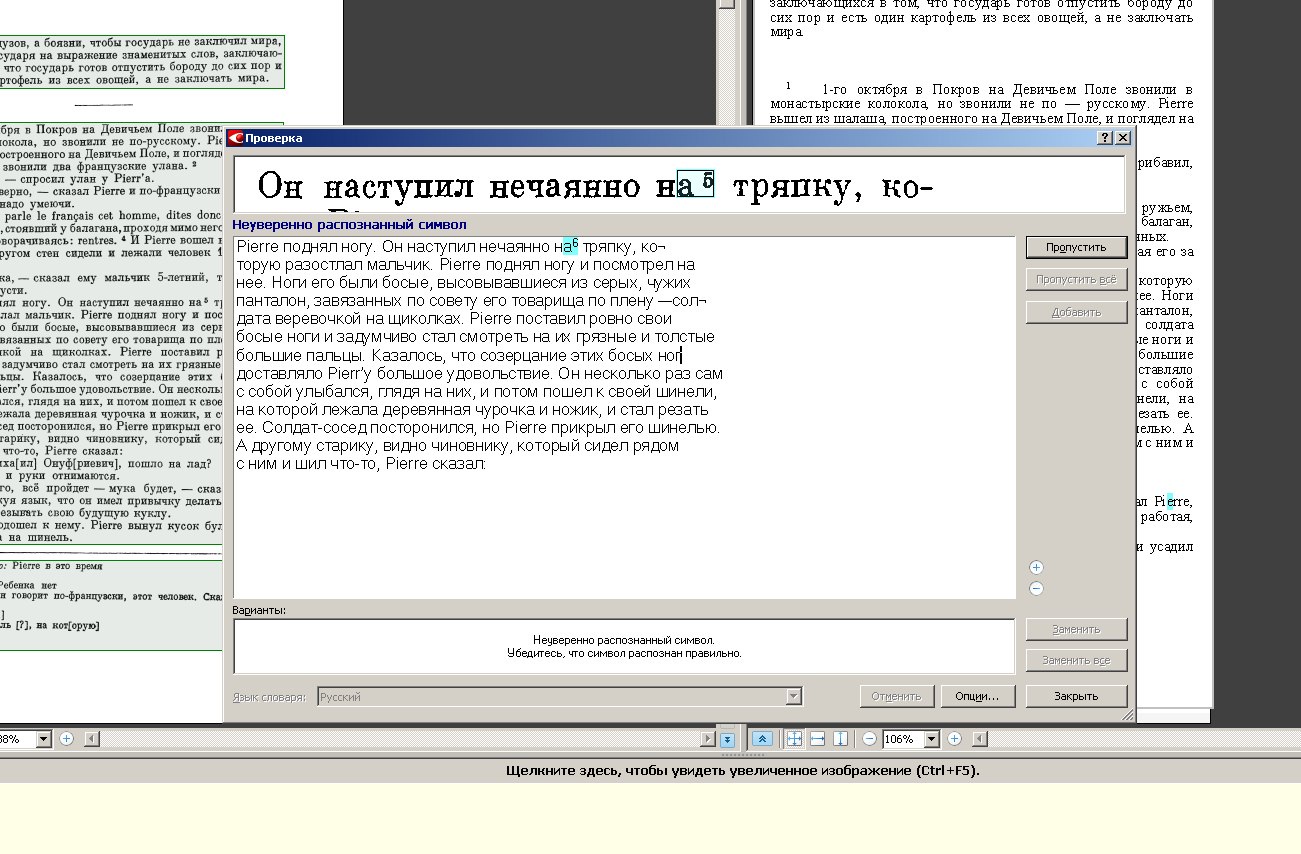
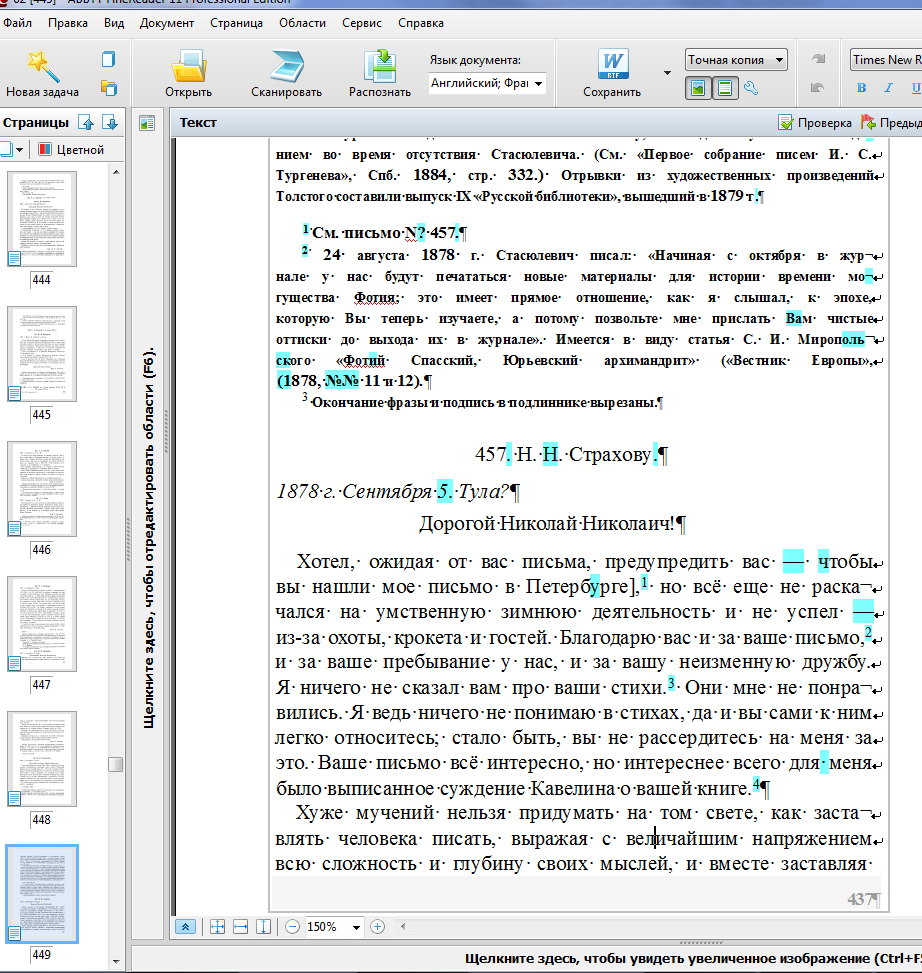
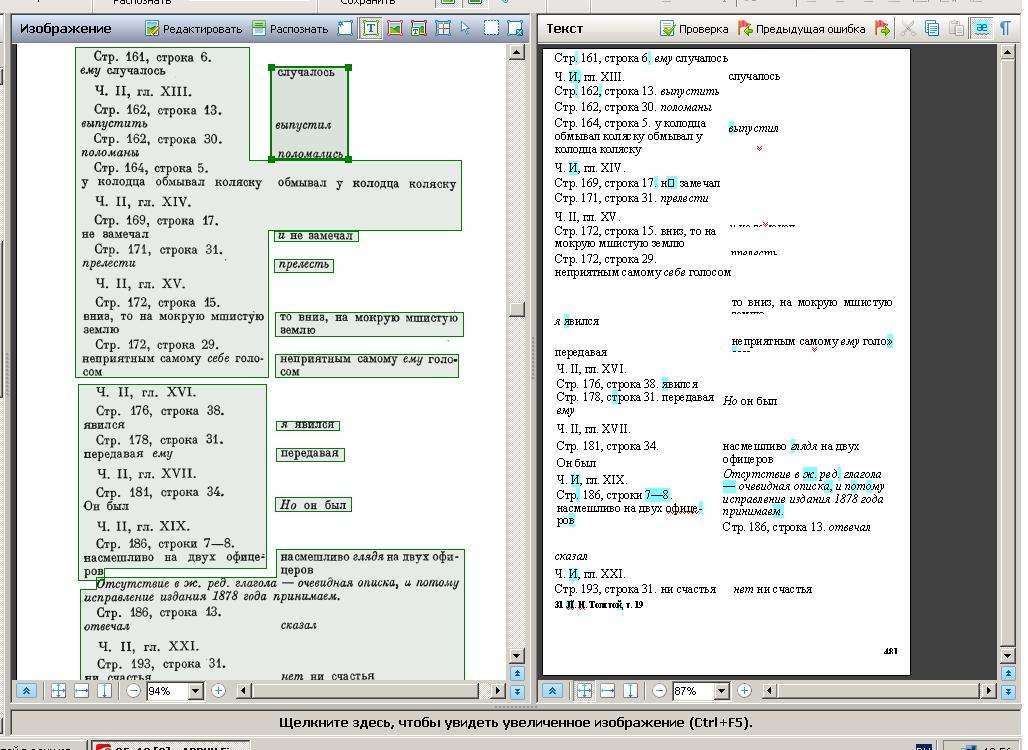
Волонтёры корректировали правильность разметки областей и сам текст:
Перед волонтёрами ставилось две задачи. Первая – проверить правильность разметки областей. Внимательный читатель скажет – ведь это уже было сделано на прошлом этапе. Но при распознавании правильная разметка областей – это примерно половина успеха, поэтому волонтёры тоже должны были убедиться в том, что документ размечен правильно. Вторая – проверить неточно распознанные символы, сравнить результат распознавания с оригиналом и исправить ошибки. Ошибки были двух видов: неправильно распознанные символы в тексте (там, где качество скана было плохим) и в расположении абзацев – абзацы иногда склеивались или, наоборот, разбивались там, где не надо.
Ещё люди должны были корректировать разбивку страницы – в случае переноса слова с одной страницы на другую нужно было «склеивать» слово и оставлять его целиком на одной из страниц. В помощь волонтёрам давалась подробная инструкция.
Пакет нужно было проверить и вернуть на сайт в течение 48 часов. Как мы помним, участник скачивал заархивированный файл и в том же виде должен был его залить обратно на сайт. Если пакет не возвращался, он попадал в выдачу во второй раз. [7]
Работа сразу пошла быстро, первую вычитку провели за пару недель

Второй этап вычитки так же производили волонтеры:
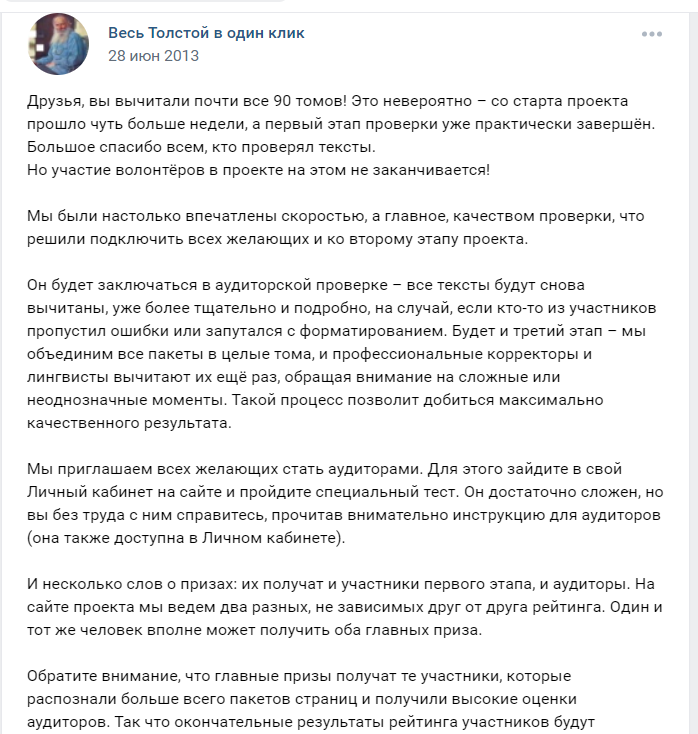
Этот этап подразумевает более тщательную проверку текста. Чтобы принять в нем участие, нужно было пройти непростой тест на сайте читаемтолстого.рф. В итоге его одолели 226 человек – они и стали аудиторами. Волонтерам-аудиторам был выделен свой призовой фонд. [8]
Отобранные на втором этапе аудиторы, проверяли результаты вычитки и могли отправлять их на доработку.
После аудиторской проверки пакеты сливали в файлы томов:
После этого пакеты поступали в специальную базу на сайте. Когда были готовы все пакеты из одного тома, администратор проекта видел это, скачивал все пакеты тома с сайта и собирал обратно в единый документ (всё ещё в формате FineReader) с помощью специальной утилиты, которую написали наши разработчики. Потом наш сотрудник проверял, правильно ли собрался том, не сбита ли нумерация страниц и т. п. После этого готовый том передавался обратно администратору. [9]
В августе начался третий этап:
После окончания второго этапа начался и продолжается третий — все пакеты объединили в целые тома, которые вычитают профессиональные корректоры и лингвисты. [10]


Хотя качество работы аудиторов было выше всяких похвал, мы все же хотели перестраховаться и устроили третий тур проверки текстов – на этот раз целыми томами. Из числа волонтеров мы сами выбрали 30 человек, хорошо зарекомендовавших себя на первых этапах, – они стали «редакторами», кроме того, на этом этапе к нам присоединилось небольшое количество новых волонтеров – лингвистов и профессиональных редакторов. [11]
Редактор мог брать на проверку только целый том, по времени работа была ограниченна неделей, проверку можно было сдать частично — указать кол-во проверенных страниц.
Четвертый этап вычитки проводили уже полностью специалисты компании ABBYY:
После третьего этапа проверки администратор экспортировал тома в формат MS Word и они отправлялись на проверку нашим штатным редакторам. Редакторы снова вычитывали файлы, исправления вносились как в Word-файл, так и в исходный пакет FineReader (для облегчения последующего сохранения из него в другие форматы).[12]
После третьего этапа специалисты компании ABBYY совместно с компанией WEXLER.QuadLab сгенерировали электронные книги и разместили их на сайте, проект завершился в декабре 2014.
Файлы электронных книг
Рассмотрим детальнее электронные книги на сайте tolstoy.ru.
Содержат сканы и распознанный слой текста. Оглавление не встроено.
HTML
Номера страниц отображаются по краям страницы, справа номер страницы которая начинается на данной строке, а слева номер страницы которая закончилась.

Примечания, в данный момент, не работают из-за ошибки в ссылках. Оформлены с помощью якорей
// ссылка на примечание
quelque chose cette nuit?<a href="index.xhtml#n7" id="backn7" type="note">[7]</a> — сказал Гальцин
// примечаение и обратная ссылка
<div class="section" id="n8">
<h2><a href="index.xhtml#backn8">8</a></h2>
<p class="left"> [Какой красивый вид!]</p>
</div>
Присутствует оглавление, оформлено так же посредством системы якорей.
Словари, указатели имён и другая дополнительная информация не размечены.
Другие форматы
Другие форматы есть для большинства, но не для всех томов:
Детальный анализ других форматов не производился.
Том 91, указатель
Отдельный интерес представляет на сайте. Том содержит
- Алфавитный указатель произведений,
- Алфавитный указатель адресатов,
- Алфавитный указатель имен собственных,
- Хронологический указатель произведений.
На сайте реализован поиск по этим указателям (возможно, не по всем) и возможность прямого перехода на веб-версию тома на указанную страницу.
Кроме этого можно посмотреть граф совместных упоминаний, совместным упоминанием считается нахождение на одной странице.
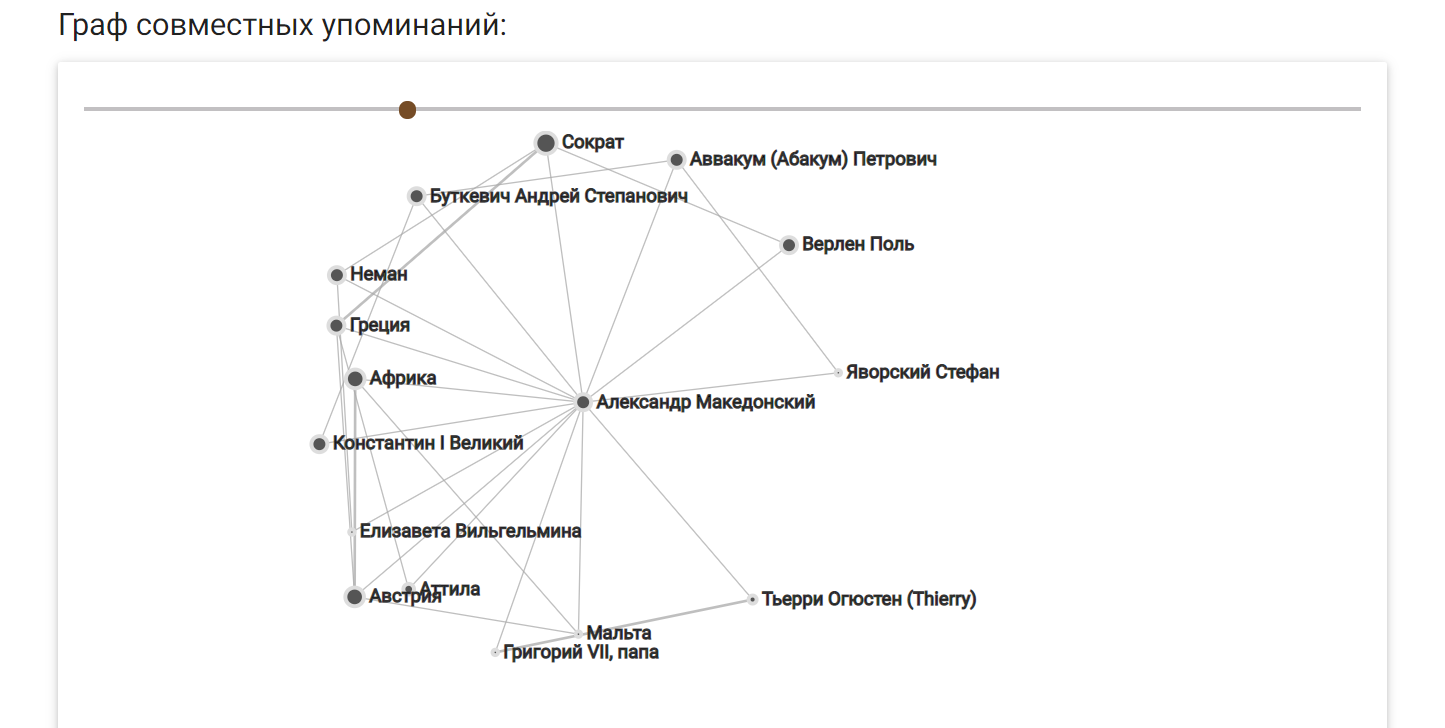
Данные для построения графа можно скачать в формате XML.
Заключение
Попробуем проанализировать проект с точки зрения задач текстологии. В первую очередь проект интересен организацией массового привлечения волонтеров для вычитки и получением выверенного авторского текста для крупного собрания сочинений. На этом заканчиваются как цели, так и достижения проекта. Рассмотрим недостатки в отдельности.
Примененный подход показывает отношение к вычитанному тексту как к один раз установленному и больше не изменяемому. Полученные на выходе файлы электронных книг трудно или невозможно поменять, например, если будет обнаружена новая опечатка, пропущенная на всех этапах. Связь с исходным сканом утеряна где-то на этапе между конвертацией файла в формате FIneReader в другие форматы. Несмотря на огромную работу это именно разовая работа, которую просто так не повторить как её участникам, так и другим группам. Текстологическая работа же должна быть воспроизводима во всех своих аспектах, как технических так и организационных.
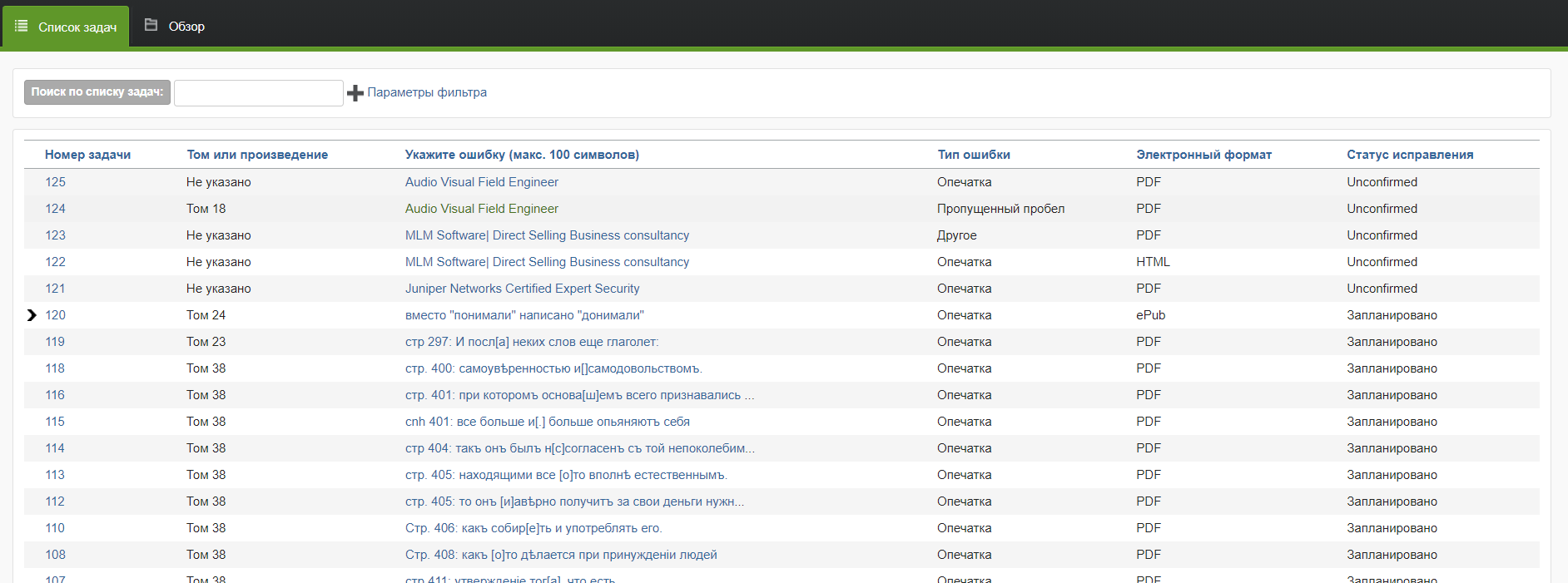
Так как детальной информации нет, даже сейчас не ясно, исправлены ли все найденные ошибки или нет. В одной из систем на сайте они отображаются, но насколько этот список актуален неизвестно:
С точки зрения обобществления результатов, в публичном доступе, прежде всего, не хватает исходных сканов. Файлы в формате FineReader после вычитки так же не распространяются. Это не позволяет работать с исходным материалом и строить на его базе другие проекты. В открытом доступе распространены только электронные книги, предположительно, распространяемые свободно, хотя в подвале сайта и размещается следующая надпись:

Используемые инструменты: FineReader и организационный портал — коммерческие продукты и принадлежат одной организации, поэтому их использование в рамках общедоступной текстологии затруднительно.
Из предисловия к электронным книгам. ↩︎