Технические решения для облегчения вычитки и форматирования
23.02.2026
Вычитка — это исправление опечаток после автоматического распознавания текста. Форматирование — добавление разметки: заголовков, выделений, сносок и других элементов. Это два самых трудоёмких этапа оцифровки книг. Ниже рассмотрены идеи и направления, которые могут упростить эту работу.
Оглавление
Обычные инструменты
Суть вычитки — проверить текст на соответствие оригиналу. Обычно текст и скан оригинала открыты в разных приложениях. Постоянное переключение между окнами неудобно, поэтому логично расположить их на одном экране. В операционных системах это можно сделать сочетаниями клавиш cmd + Left и cmd + Right.
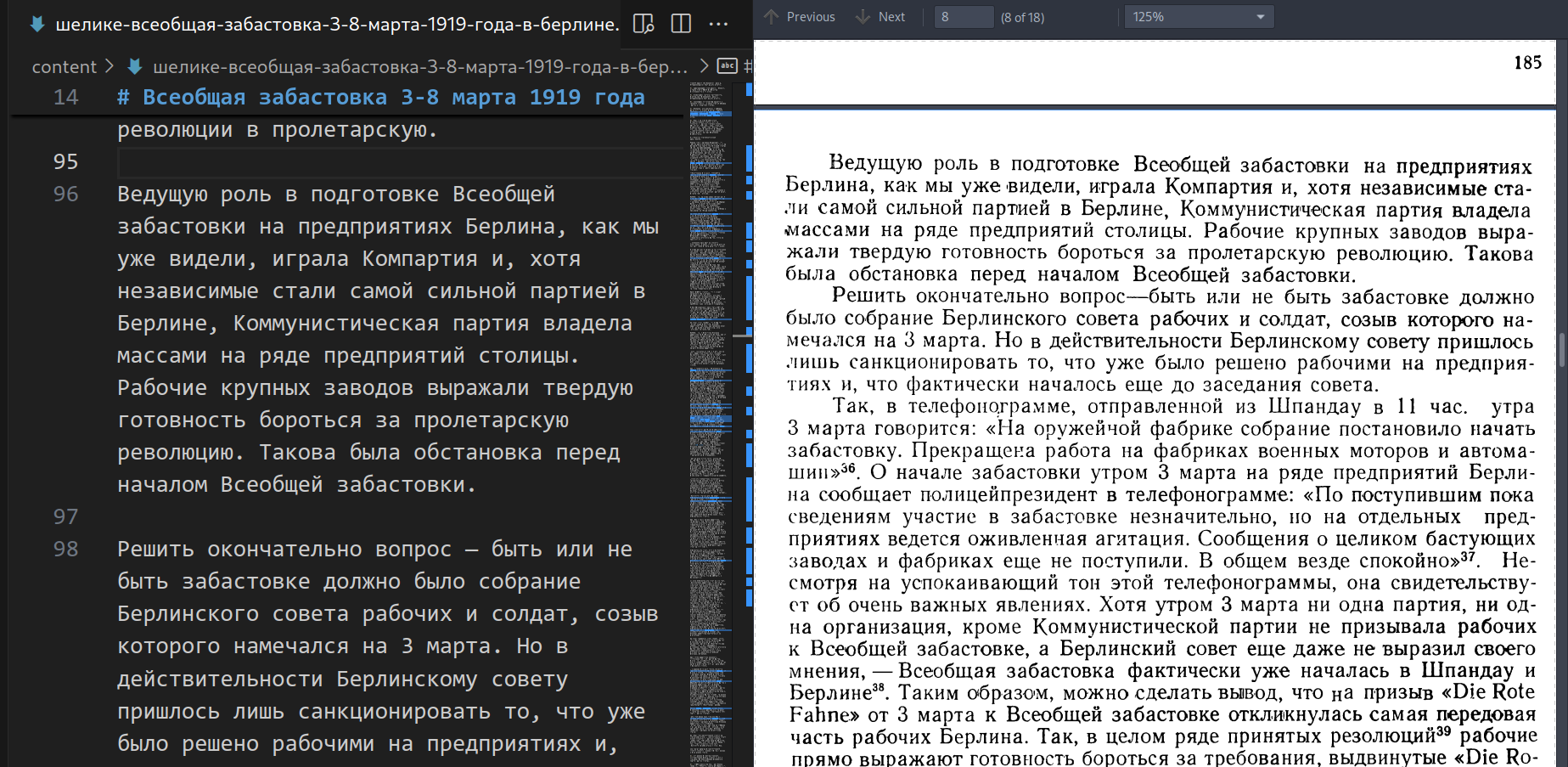
В браузерных инструментах подход тот же:
Инвертирование цветов
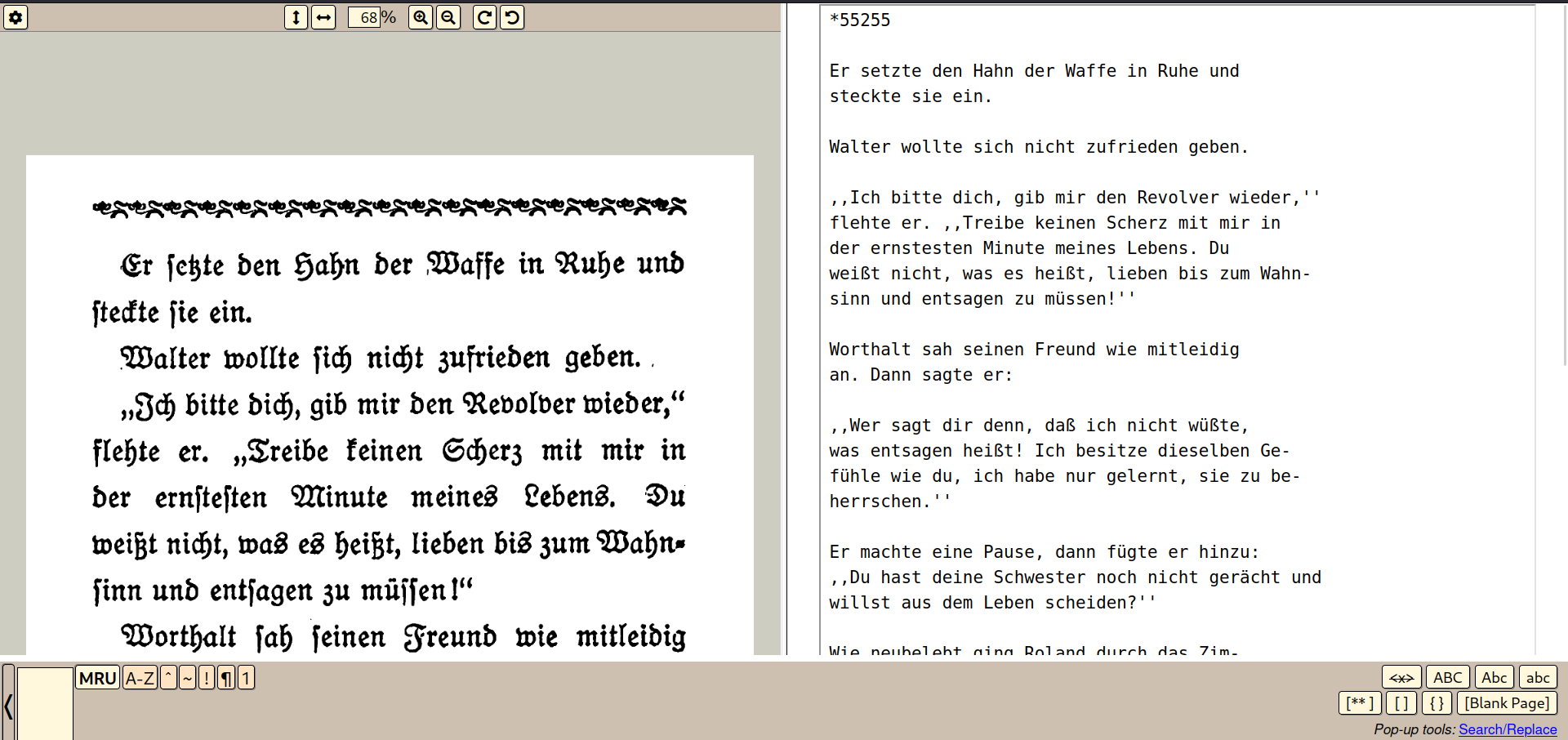
Почти все сканы имеют светлый фон. В ночной теме они слишком ярко светятся. Было бы удобно отображать их в инвертированных цветах. Пример такого режима в Atril Document Viewer:

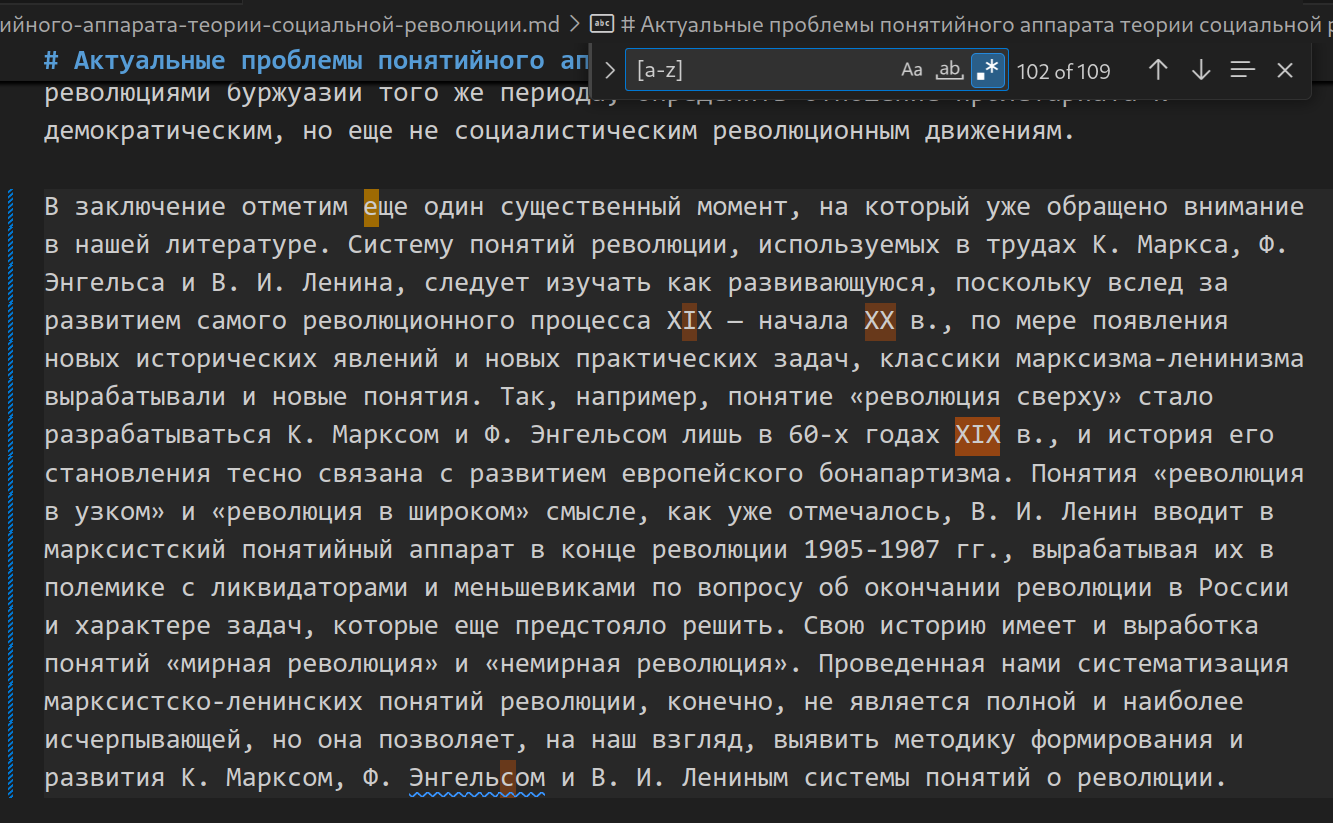
Подсветка некирилических символов
При распознавании многоязычных текстов отдельные буквы кириллицы иногда определяются как символы других алфавитов, и наоборот. Например, в римских цифрах XX и XIX может появиться кириллическая «Х». Частично проблему решает проверка по словарю, но полезна также функция быстрой подсветки или поиска таких символов. Пример реализации в VSCodium:
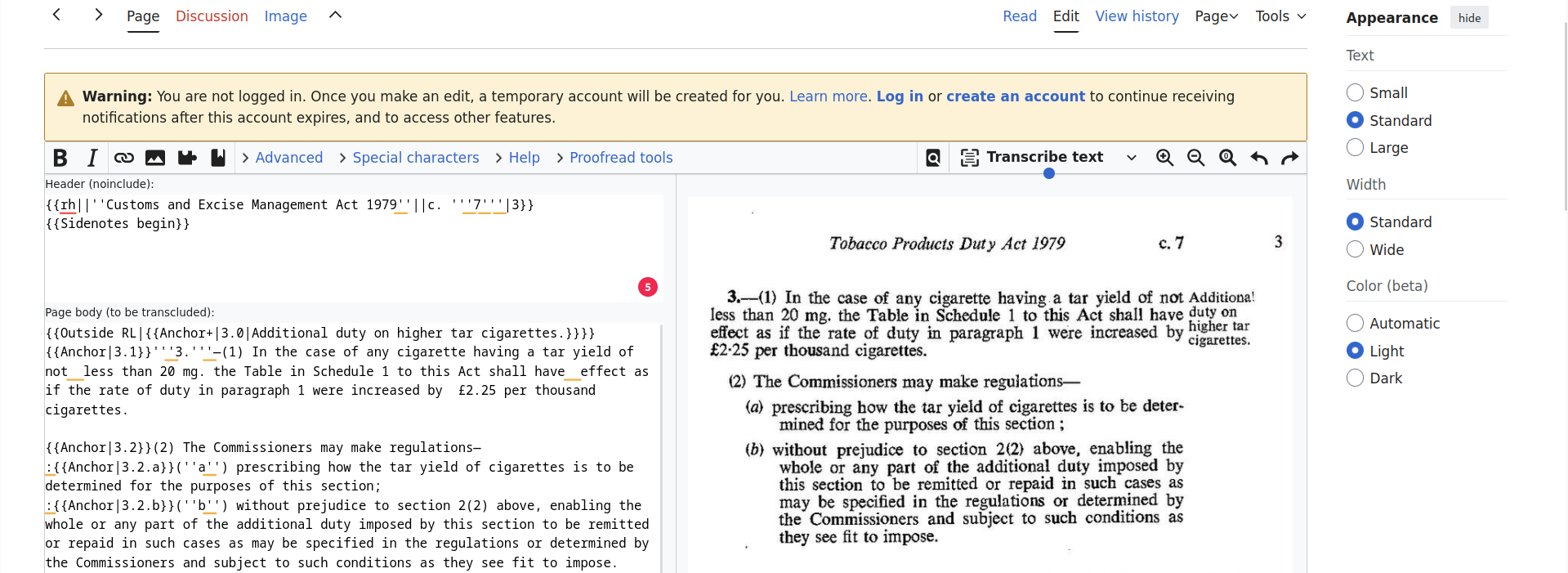
Проверка по словарю
Проверка по словарю находит много опечаток, но даёт и множество ложных срабатываний. Поэтому нужен словарь, который пользователи могут пополнять совместно. Также проверка должна учитывать особенности формата Комтекст и редактора. Например, слово может начинаться на одной странице и заканчиваться на другой. Иногда часть слова выделяют жирным или курсивом для акцента: **Философско**-экономические рукописи.
Пример такого словаря, но сейчас им пользоваться неудобно.
Постобработка текста после OCR
После OCR полезно выполнить ряд автозамен, например заменить все последовательные пробелы на одинарные. Список таких замен требует отдельного рассмотрения.
hOCR формат
После OCR доступен не только текст, но и специальная информация о положении каждого символа на изображении. Часто для этого используют формат hOCR. Это HTML-код с добавленными координатами каждого слова.
Пример части документа в формате hOCR:
<p title="bbox 147 706 1316 1898" class="ocr_par" id="par_1_3">
<span title="baseline 0.002 -11; bbox 191 708 1315 750; x_ascenders 10.407609; x_descenders 10.221519; x_size 42.098957" class="ocr_line" id="line_1_4">
<span title="bbox 191 708 382 747; x_fsize 10; x_wconf 87" class="ocrx_word" id="word_1_13" lang="ru_RU">Индивиды,</span>
<span title="bbox 422 718 674 750; x_fsize 10; x_wconf 95" class="ocrx_word" id="word_1_14" lang="ru_RU">производящие</span>
<span title="bbox 714 719 731 739; x_fsize 10; x_wconf 95" class="ocrx_word" id="word_1_15" lang="ru_RU">в</span>
<span title="bbox 772 710 941 747; x_fsize 10; x_wconf 93" class="ocrx_word" id="word_1_16" lang="ru_RU">обществе,</span>
<span title="bbox 957 727 997 731; x_fsize 10; x_wconf 91" class="ocrx_word" id="word_1_17" lang="ru_RU">—</span>
<span title="bbox 1009 719 1028 741; x_fsize 10; x_wconf 72" class="ocrx_word" id="word_1_18" lang="ru_RU">а</span>
<span title="bbox 1050 718 1315 748; x_fsize 10; x_wconf 96" class="ocrx_word" id="word_1_19" lang="ru_RU">следовательно,</span>
</span>
Подсветка возможных ошибок
Поле x_wconf в файле hOCR содержит степень уверенности движка в правильности распознавания символа. Эти данные можно использовать для подсветки сомнительных мест. Поскольку в hOCR есть координаты символов, подсветку можно отобразить одновременно и в текстовом редакторе, и на изображении.
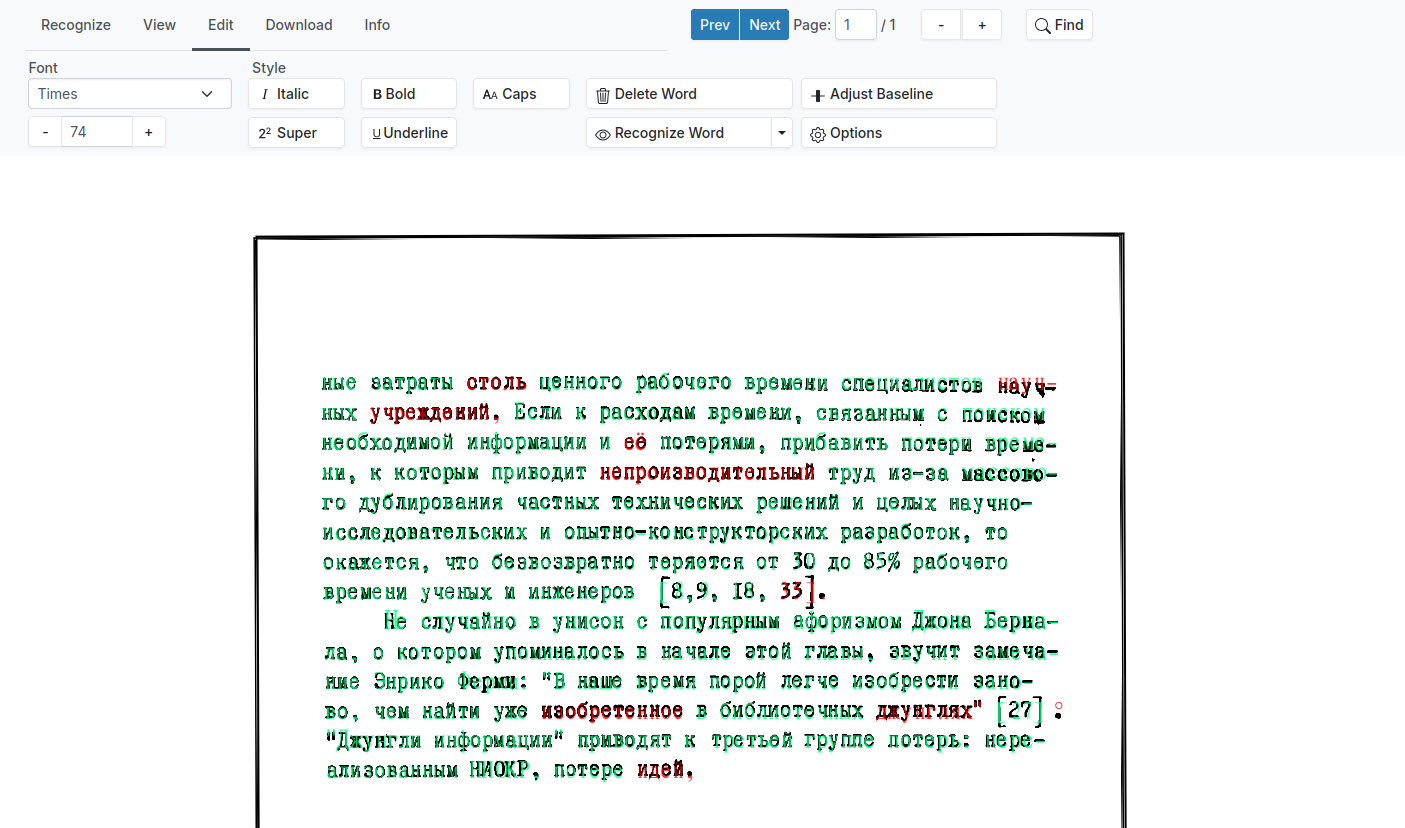
Редактирование поверх изображения
Возможно, удобнее было бы вычитывать текст прямо поверх изображения. Это экономит место на экране: вместо разделения окна на две части остаётся одна рабочая область.
Похожий функционал реализован в Scribe OCR. Там сразу предусмотрена подсветка символов, требующих перепроверки:
The second shows Scribe OCR’s Proofreading Mode, which precisely layers colored OCR text over the source image. In addition to overlapping poorly with the underlying image, most errors are also colored red, which indicates the OCR engine flagged them as low-confidence.
Автоматический фокус на изображении при выборе текста
Если текст и изображение разделены, изображение может автоматически прокручиваться к фрагменту, где стоит курсор. Это ускоряет поиск опечаток в оригинале.
Пример реализации — hOCR-Proofreader.

Улучшения OCR
Качественное распознавание символов облегчает вычитку. Помимо точности символов, важны функции, ускоряющие форматирование.
Например, Tesseract распознаёт только текст, игнорируя таблицы, изображения и выделения (курсив, жирный шрифт). Другие библиотеки лучше определяют структуру документа и стили текста: например, PaddleOCR или Surya. Также существуют инструменты для распознавания отдельных элементов, такие как LaTeX-OCR для формул.
Даже простое определение жирного шрифта и курсива значительно облегчило бы работу. Например, сервис datalab.to корректно распознаёт курсив в русскоязычных текстах.
Множество идей можно найти в подборке awesome-ocr.
Заключение
Это неполный список способов упростить вычитку и форматирование. Отдельная тема — использование нейросетей для поиска опечаток. Для этого нужен специальный интерфейс или специально обученная модель: при обычном использовании нейросеть может внести больше ошибок, чем исправить.